Getting More from Every Copilot Interaction
Chapters11
Host introduces the stream's purpose: to help viewers optimize Copilot billing and reduce waste without panicking about the changes.
A practical guide to getting more value from GitHub Copilot by optimizing usage, models, and budgets without sacrificing productivity.
Summary
GitHub's Getting More from Every Copilot Interaction is a candid, signal-packed session led by Andrea with insights from Franchesco, Marco, and Arlene. The team lays out how Copilot is moving to usage-based billing and walks through practical steps to tune workflows, choose cheaper models when appropriate, and avoid wasted tokens. Francisco demonstrates where to view usage, set budgets, and understand the new AI credits system, while Marco emphasizes model selection tactics and pacing your prompts to reduce cost. The group shares a practitioner’s guide they assembled to help teams optimize cost, including tips on starting conversations fresh, crafting concise prompts, and using instructions scoped to specific files. They also discuss enterprise controls like user-level budgets, cost centers, and how to segment spend across orgs to prevent surprises at month end. The conversation is peppered with real-world advice on model choice (Opus vs. cheaper GPT variants), how auto model selection works, and the importance of token-conscious prompts. By the end, the takeaway is clear: adopt smarter habits, balance model power with cost, and set up budgets now to avoid budget blowouts later. The session closes with encouragement to share resources, refine personal instructions, and keep Copilot as a productive ally rather than an expense spike.
Key Takeaways
- Usage-based billing is the new default for Copilot; expect costs to accrue based on tokens, context, and tool overheads.
- Use the usage dashboard and CSV exports to monitor consumption, set budgets, and identify top spenders within your organization.
- Switch to cheaper models when task-appropriate (e.g., prefer GPT-3.5/GPT-4 variants or other models for non-critical coding tasks) to dramatically reduce costs.
- Enable and tailor user-level budgets and cost centers in the enterprise to prevent runaway spending and to align cost with teams and responsibilities.
- Adopt prompt discipline: start fresh conversations when context bloats, compress prompts, and limit output tokens with techniques like caveman speak to save costs.
- Leverage local or custom models where feasible, and use auto model selection to ensure the right model is chosen for each task.
- Organize and trim Copilot instructions and MCP servers to reduce context size and avoid unnecessary token burn.
Who Is This For?
Essential viewing for engineering managers, DevOps leads, and developers who rely on Copilot in larger teams or enterprises and want to control cost while preserving productivity.
Notable Quotes
""We are moving to from premium requests to usage-based billing... charged for actually the usage we will have.""
—Francesco explains the billing shift to AI credits and how usage affects charges.
""Start fresh conversations... when you notice you’re going in circles or the token window is filling up.""
—Marco/Francesco advise managing context to save tokens.
""The idea here is not to panic and to be terrifying and think well that’s it. I can’t use Copilot anymore.""
—Andrea framing the session around practical optimization rather than fear.
""If you don’t care about explanations, you can output only code... and you save essentially output tokens.""
—Guidance on prompt design and token savings.
""Use cheaper models when the task merits it; the frontier model isn’t always the right tool for every job.""
—Advocating for balanced model selection to optimize cost.
Questions This Video Answers
- How do I set up usage-based billing budgets for GitHub Copilot in an enterprise?
- What are AI credits in Copilot and how do they affect my monthly bill?
- Which Copilot models should I use for coding vs. heavy reasoning tasks to save tokens?
- How can I limit Copilot usage by user or department in my organization?
- What strategies help reduce token consumption when using Copilot with agentic workflows?
GitHub CopilotUsage-Based BillingAI CreditsModel SelectionToken OptimizationPrompt EngineeringEnterprise BudgetingMCP ServersCost CentersAuto Model Selection
Full Transcript
out. Hey. Hey. Hey. Heat up here. Heat. Heat. Hello everyone. Good morning, good afternoon, good evening, whatever in the world you're joining at. Let's get rid of this music for one. But welcome, welcome, welcome. Thank you for joining this stream. I have to apologize in advance. I am not in my office as you can tell from my background. About 10 minutes ago, my entire community had an internet outage, so I had to run to a coffee shop. So you might hear some background noise that you typically don't during this kind of stream and I am so sorry for that but the show must go on.
What we're bringing you today is something that is top of mind for every single one of you here. Let me introduce myself first. I'm an a senior developer adex here at GitHub and I get to work with developers every day. This stream is not going to be a feature demo although we are going to tase you through some of the ways that you can optimize your billing and look at the bill which I know everyone is concerned around. Uh but we're going to see what we can actually do about it. So let's sort of set the right frame to start.
The idea here is not to panic and to be terrifying and think well that's it. I can't use co-pilot anymore. The idea here is that we need to optimize for right. We're going to stop wait for interactions and we're going to work in ways that help efficiently make a real difference and what our cost is. So that's what we're going to cover. I'm super excited because I'm joined by two people that been building material on this. They get to talk to customers a lot probably every day is literally their job and they've been very concerned as many of you have about how this is going to impact us on individual level for their own accounts as well as an enterprise level.
Welcome Franchesa and welcome Mat Olu. Thank you. Thank you. Welcome everyone. Thank you for being here. And so you both have been working on a resource uh for a practitioner guide that we we're going to share actually. Um we created a ton of information. We're going to cover some things here during this stream. We're going to show you how to look at your feelings and then we're going to talk about what you can do to actually optimize it. Uh but first we need to also give thanks to Arlene who is not here but he's one of the contributors and I'm probably completely mispronouncing his name uh Marco you can correct me uh but he's one of the people who contributed to um some of the guides that we're going to be sharing today.
So let's get right into it. We're going to start with what's actually changing and basically if you seen the the if you seen the announcement to read the laws you understand now that there is going to be a different way of dealing for the cop pilot. So we need to sort of shift our mentor model and the way that we are thinking about how we work with copilot and that is UB. Someone in the chat asked really earlier what UBB is. So there is your answer is actually usage based billing. So we call it usage based but it's basically how do you spend your tokens right?
So that's that's it. Um we used to have an unlimited model before just a good time and now we have a meter model right so the key to understand that is that it's shaped by different things uh the way that your usage is used uh the prompt inputs the model inputs the context overheads the tool overheads and there are many things that we can do to optimize that and that's something that Marco and Franchesco are both going to help us for today. So uh we're going to think about the ways that we can optimize not only for our organizations but on our own personal uses.
Right? There are things that remain free and that's we should also highlight that that there there are still ways that we can use copilot uh and not consume that part of your allocation of your users like the inline completions and next edit. So those things stay outside of the new credit system. But what Burns models is of course the premium models, the travel context, advanced completions, agentic workflows, all of that. So what I want you to take away from this session today is that we need to not worry so much about setting up budgets per se because I budgets are just going to cut spending.
And the idea here is not it's not a punishment. It's not intended for you to use less a tool that become so important in all of our developer workflows, but to just learn better habits so we know how to reduce waste. So we can set the budget sort of stop the reading and then there's going to be real efficiencies that we're going to gain coming from the way that we change our workflows. So that's what this stream is about. So what's actually changing? Let's go over the timeline real quick. On June 1st is when usage based stealing is going to flip on for teams and for enterprise.
So if you're using copilot today, you want to be looking at your baseline usage before that date. And that is what our friend Francesco is going to actually take us through. Francisco, if you could take us through where we're supposed to find this billing guide and how can people take a look and see exactly make sense of what it is. Yeah, sure. Sure. Thank you, Andrea. Uh, I hope you can see my screen now if we can switch up. Okay. Okay. Here, here it is. So what happens actually um probably you already noticed landing on your GitHub page uh you um developers will notice that there's like a new badge says that copilot github copilot is moving to a credits.
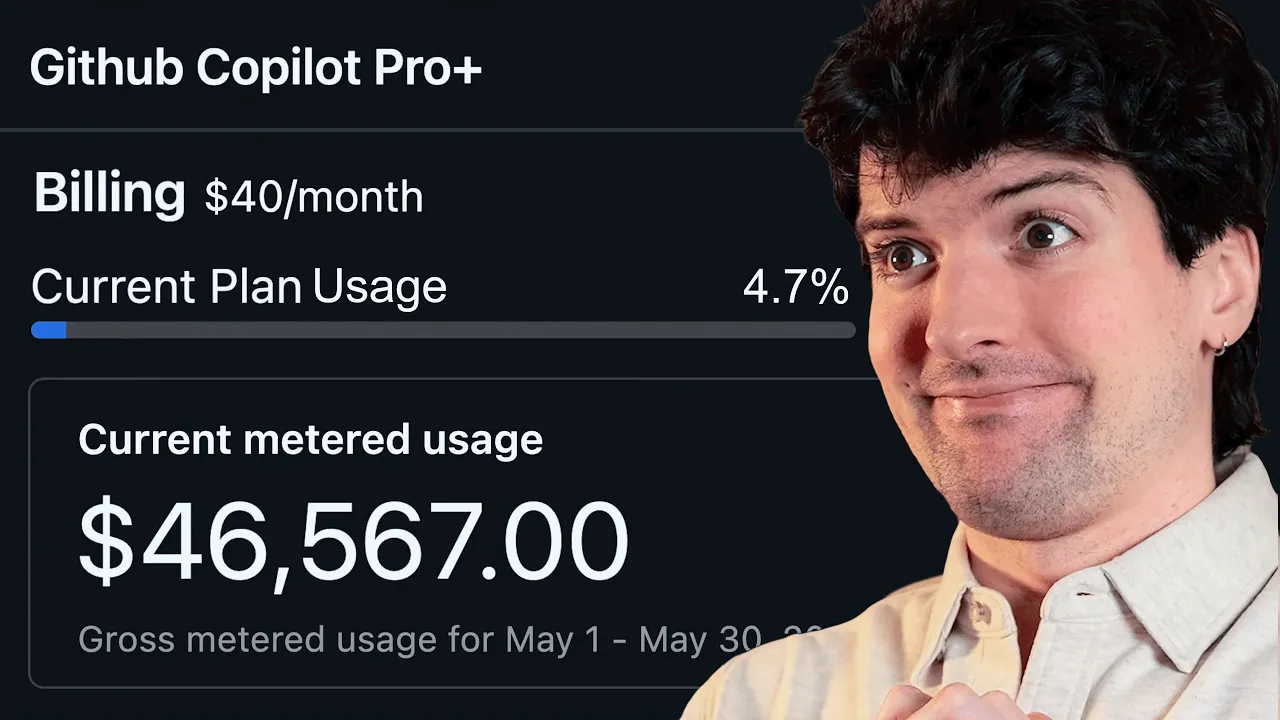
So what does it mean? Of course thank you for the introduction Andrea. So uh we are moving to um from premium request usage to AI credits. So uh we will um be um um charged for actually the the actual usage we will uh we will uh we will have. So what developer can do can just if you click on preview your usage you can of course go through the documentation you can set budgets you have code uh you have CDAS that will drive you to the documentation or uh some some of the action that we will see later on also with Marco and then you can download the CSV CSV file that we will give you the um preview on the usage based on the uh on April.
So um if you click on this uh an email will be sent uh uh of course uh uh to to your to your email and then and then you will be able to um upload it into the uh site dashboard we uh um have um released. So if you click on the explore usage and trends you're going to um re um redirect to the the uh sidecar application. Here you can see uh this is going to explain the user based billing how it works and you can of course upload your own CSV. I got some someone here like um for demo purposes I can upload so we can see how how it works.
Just give me one second. Here it is. Please just don't look at numbers. These are are just some fake data we we fill into just to give you like this this demo. But anyway, here you will find like a dashboard that is reporting based on your core your current usage in April. Um how this will look like uh in the next few months. This is just an estimation an idea could be less also could be more depending on on your usage. I wanted to say also that um here all the values are provided without any discount.
You may have promo or whatever. Uh but in this um estimation um you will see the promotional amounts applied. I mean um as far as you you understand um we have like a promo period going through uh um June, July and and August where you will have a bit more of entitlements that in that are included in this standard um tier. So um this is important because you you will have some time to adapt to uh let me say tune up your solution your um your your configuration uh on on GitHub and on GitHub and um this is um this uh dashboard is pretty helpful because a part of the let me say just the the the value amount I mean the cost amount you can also go through and check it all the recommendation recommended next steps You can also navigate and better understand how developers are using the tool.
So for example, if we navigate in the user, you can see the uh total the the pool because this is this is another news. Um you will have now share a pool. So when developers will um make a subscription for GitHub, they will have like I don't know maybe an amount of AI credits. But like before before you you have premium request with premium request you have like a pre-user uh bucket and then all the all only the overage was like sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh share pool.
Right now what you have you have like a share pool from from the start. So this is like a cool thing because you can also save up on for example like user that were where not using all the premium requests as money you don't have any waste. um looking at looking at the looking at the user. This is this could be something interesting. You can sort for PR usage or for a AI credits and have like an idea on how your user are using I mean the the Gap pilot. You can also navigate through the model tabs and see which is the model that is most used.
Uh you can see sorry for pure model or you can you can look at the top models also used. Um you can also navigate products and see which is the product that consume most. In this case for GitHub copilot you can see for example I got oppus 4.6. Um maybe uh you can find something else that um have a similar comparison in terms of performance. We can dive this into later on also with Marco. But anyway, this this is very helpful to give you an idea on how you can then approach this change and adapt to this change.
And last thing is like um the spending insight. I think this is very interesting because uh can give you like um a spending by group per user. So you can see there are some power user, heavy user, typical user, light user and near zero users. So this is like a t-shirt sites group with the the users. So you can also maybe use those insights to tailor a bit more on on how you going to uh end up with setting budgets and so on. Speaking about budgets um we um also uh introduced um a fine um more fine level of uh I mean granularity of of control in in the user level budget for example.
So you can now you can now set user level budgets that apply globally or you can also make specific overrides for specific users. Um and this will help you to manage let me say hungry users not only angry users but also hungry users compared to uh maybe like user that maybe occasional user they will not consume uh so much AI credits but maybe of course they will also uh they also had the chance to use copilot and to avoid to angry user to consume all the bucket so it over to you Yeah. Yeah. Thank you.
Thank you so much, Franchesco. I just wanted to quickly ask and sorry for interrupting Marco because you mentioned uh earlier on that there is some credits that are going to be applied. So for folks who are watching that with enterprise accounts, how can they know what these credits are? I think probably the best way would be to reach out to their salesperson to understand better. Okay. Yes. um developers and I mean organization can reach out to their usually Microsoft or GitHub contacts and usually the account team uh where we we can discuss about this and see how all this promo period and all the terms applies.
Um the other thing is we we also have like public documentation. Maybe we can share that later on in in the post in the chat. uh so we can uh give you like um information specific information about the the promo period and and entitlements that you have in that period. Great. Go ahead, Marco. Yeah, just to maybe give also some hope, let me say to to all the folks connected here. I mean this these are numbers you might say, oh they are scary uh because yeah this is like the double. So, and but on the on the positive side, I've noticed a lot of people, a lot of developers and a lot of organizations that essentially are using the pattern that you were showing in one of your um screens.
So, insight oppus. Oppus the oppus the elephant in the room. The oppus of it all. Oppus everyone everyone these days is using oppus. And I mean you have been using it probably for the right reason because up to yesterday let me say it was cheap in in GitHub copilot and I have to confess that since I have unlimited tokens since I work with for Microsoft I was using it myself and when I saw many tokens I used I said oh my gosh I should do something and I would be a liar if I told you that uh yeah oppos is not great.
opposite is great but honestly I then backtracked this habit myself which I develop a lot of code um these days and I started using other models so cheaper models and probably this is the the best thing that you can do right now today just use cheaper models go check out on the official uh model provider pages the basically the pricing input output and cash tokens because all these count against your Asia uh your AI credits AIC's and choose the most appropriate one uh for for the task you're doing. So if you are like creating uh some you maybe creating a deep analysis uh deep faults well oppus is probably great it's it has great reasoning capabilities but if you're just just let me say coding set or GPT3 uh 5 53 uh codecs are very great and maybe if you created a plan with OPUS you can implement with a very cheap model like I so yeah is to say that uh not always the best model is the best actually the the best solution that you should you should pick and if you bring away one thing from this webinar that's it try to use cheaper models and you will see that the results are great the same also uh one one thing that I I I can share is that and quite it's also quite easy to to understand is that often these models come with reasoning efforts you can tune.
So you can basically decide how much each of these LLMs thinks about tokens and thinks in tokens when you you do a prompt and uh as in real life if you spend too many thoughts on a simple program problem you might lose a lot of time and you might not even get a good result. So my suggestion is also to tune the reasoning effort every time you face a problem with agentical workflows. Uh just think I'm trying to solve a very small issue which maybe I is a great fit or is it like sending a rocket to the moon.
So that is probably the job for Opus. Okay. So just just balance uh these things and they will impact a lot on your consumption. I think yeah I think that the difference between IU and Opus or GPT5.5 is 24 times in terms of cost. I I read it somewhere. That's crazy. It's crazy. It's crazy. So choose the right model. Okay. So to sum up to sum up we can also apply as you said we can also apply like dividing par so taking tackle the problem um divided by into small chunks or let me say atomic operation and then address it with maybe we can use like I don't know maybe a reasoning model to have like a a bigger plan and then go deep down to the single task with like an I could you can save up to I don't know maybe 60 times yeah that's that's something we can Yeah, I think we just all build I can speak for myself as say we but I definitely build some really bad habits like just taking a hammer through everything is not the solution and there is a lot of models that are very efficient and sufficient for what you need but you know before what we were concerned about just like of course throw the most highly reasoned model to everything and often times honestly it does not give you the responses that you would actually work with and I think it just adds layers of complexity to simple tasks that are not necessary.
There is a new feature also in copilot uh that the auto select mode where there is some it's been super interesting for me to learn. I was extremely skeptical about the auto model selection. I always think automatically assume it's cheap the cheaper models are going to pop up automatically because this is an efficiency for the provider not for the user. But I I sent corrected after actually spending some time with some of the engineering and PM team and I share on the link uh on the chats. Um we did a job check out recording where the PM for this auto feature actually goes into details about how they do a benchmark in the mode and selection as to what get assigned for what task and there's a lot of intelligence layers that go into that and she does a demo actually as part of the the episode that shows that the correct model got chosen for the correct task and it wasn't the cheapet model right like it's still selecting clock pair models when the task merits the frontier model otherwise it's actually giving is a a a less expensive model but not a bad model, a model that's the right model for the job.
So we just got to sort of make a mental shift about how we work using the different models for different tasks. Breaking it apart, breaking the problems apart and that's you know the basics of our software engineering like you mentioned Franchesco but we all got so used to being able to just throw one request to an agent and let it go run on one premium request that it's not been a concern. So I would encourage everyone to give auto model selection a try as well. That is it's it's a good it's a good um tool now.
It's changed a lot. If you used it before, try it again. Um but I want us to transition into the nitty-gritty of what we can do. There was a question earlier in the chat. Uh and thank you so much Michael for being here about cloud strategies for reducing usage consumption and preventing that rate limiting on the agentic workflows. And I think that is exactly the kind of thing that you were working on Marco, Franchesco and Arling on that interaction cost guide. So if we don't mind just transitioning into that because I think that that complements very well what we're talking about here that it's like let's not plan it.
We just want to learn how to use copilot better and to identify those usage drivers right from the getgo so we can adapt our workflows to where we can actually save some bill money. Microsoft. Yeah. Yeah. So basically I have created this repo uh which I created initially internally at Microsoft to collect the various techniques that uh you know are like available uh in many different and sparse uh places on the internet. Um so this is not official guidance let me say from GitHub or Microsoft but uh it it contains quite a lot of suggestions and there are GitHub pages from here you can click this link so you will be brought here so we collected this token optimization guide just several suggestions which uh we will go through now uh so maybe let's skip why tokens matter because now now you know it and let's let's see how you can compress well one technique which was created by um I I don't remember the name of the guy that created a few months ago is like caveman speak.
So you uh the principle is that you can avoid a lot of articles, fils, pleasantries and edging to save output tokens essentially. And that's a good idea because output tokens are uh quite expensive in all the models overall. uh even though they are less than the input and cash tokens but they they they impact quite a lot since they have a higher cost. Uh so applying this uh this technique is as simple as uh instead of asking and having the model say can you explain what is the message means now I should fix it explain error how fixed now it's more uh I would say harsh um but uh it works uh decently well especially if you apply uh the not maybe not the ultra variations But lighter variations you still get uh good quality of outputs without losing anything uh in uh I mean in terms of quality.
So there are intensity levels that you can uh decide. So you can be like professional but tight so uh like this and this is about 20 tokens or you can go full caveman um so very very harsh or extremely harsh. There are estimations which are available available on the internet. Uh take them with a grain of salt here. But uh in in general they save output tokens as we said and it's quite simple also uh if you start maybe uh thinking twice when you type your prompts. So instead of typing a very long prompt like this, you could maybe restructure it in a condensed way.
Maybe it won't be easy at the very beginning but maybe you can um can put a lot of more effort in in your prompts to save also uh your your input tokens. Uh so you can use abbreviations for example. So instead of writing database you can write DB uh and so on. They might uh be in some cases one token instead of two or three tokens. It depends on the language and so on and also on the language. Let me maybe switch I think to the second uh suggestion is that well you might be uh English native uh but I am not Franchesco is not well we I speak in English to to my agents uh only very little in my native language which is Italian uh but uh I have seen uh people uh actually preferring their own native language for input tokens and subsequently also also for output tokens because if you start writing in one language the model will output probably in that same language.
Uh it's a bad idea because on average there is at least one uh 30% uh more tokens in output to tokens in general for another language and some on some languages it's even crazier especially like in Hebrew or Russian or Japanese. So try to use English language when talking to the models because you will save tokens not words maybe but tokens actually there is something like this uh Chinese uh classical which I don't know how it's pronounced it's when you don't speak Chinese mark but I don't speak Chinese so if you speak this uh actually you can save even more but it's just more for actually educational purposes in general use English and use thirst English so that uh everything is uh more condensed.
Uh don't translate your prompts and if you believe just right uh English um then uh maybe we can uh touch uh touch this. So uh we all know that uh copilot instructions is typically the first file that uh you you want to create in your repo. That's fine. There is also the slashinit command in VS code and I think also in the cop cla uh maybe also on other uh ids. Um I don't use it personally. I tend to write my uh custom uh copilot instructions manually and I uh prefer to put there only the things that the model the model couldn't probably figure out alone maybe um I give you an example so I had this project which was using posgress SQL on my machine I was building it and actually I had the posgress SQL containerized.
So every time I had an issue with the database, I noticed that the agent went in circles many many times trying to find the psql command to connect to the database and run some queries. I had no psql on my machine. it was a docker container and he figured out after like 30 40 50 seconds and all those were wasted tokens and now that we're paying them it's very very important to tell the model hey look if you need to connect to my database it's dockerized so do a docker exec and don't try to find psql on my machine so things like this will save you a lot of tokens if you put them in copilot instructions and I prefer to put them manually very condensed.
Um, so here is the example also of using caveman in your comparative instruction. So you can write you should write the uh test responses like caveman and blah blah blah uh very very tense. So in this case with with a saving um also u if you are using uh custom instructions which are uh those in the github/instructions folder, you can use the apply to. The apply to allows you to scope the instruction files to some specific files or folders or patterns. So that's a very good idea. uh again to save uh tokens because you do not put these specific instructions for just one file across your general copilot instructions but you put them only for specific files that actually are the ones interested by those instructions.
So um also use this technique to basically organize your your repo. Um there was I think another one uh here. Yeah, this one is quite quite important. Uh and again I I confess I'm guilty. Uh start fresh conversations. Uh because when you accumulate the context at a certain point you will uh incur into automatic summarization. That's typically bad for quality but also it's quite bad for uh the D of tokens that you're consuming. So it's better than when you arrived at 50 60% of your token window filled up with the tokens or if you notice that you are going in circles you just start a fresh new uh chat.
In that way you will pay the fact that uh tokens are not cached so you have to cash them again but uh overall it tends to work uh probably better. Um okay this is similar to the the table technique. So you can ask in compile instructions for example to output only code without explanations and or you can type it in your prompt code only. So agents will tend to uh respect this and you save essentially output tokens if you don't care about all the instructions and all the uh the notes that an LLM could uh could could give you.
uh so you can save again a significant amount of output tokens and remember output tokens are few but are quite costly and this maros already depends also by the mode you you you're going to use if it's like I don't know maybe it's an ask if you're using mode for example or if you are using like a plan mode if you're using agent mode probably uh this will this is better when for example if you need to ask something of course maybe you need to have like a better explanation on on on the topics on the the subject you're dealing with.
Uh compared to for example an agentic uh um an agentic task where where you need to spin off or maybe you spin off the autopilot and you wait I don't know maybe two hours until it finish the job and then you come back and see and see the results. So that depends also about uh which is the mode because um looking back at the question before I said without compromising performance and that's why depending on which is the mode you're going to use you're going to apply different way of controls and uh and you're going to mitigate the problem in different way.
Yeah. And talking about ask mode and agent mode. Um if you are just asking for something if you use the ask mode it's slightly better because in the past it used to behave like no tools no almost reading nothing just the file that you had opened. So it was even cheaper. Nowadays it's a bit more agentic but still less agentic I've noticed that than using the agent mode to ask the same question. So yeah, maybe you can also maybe create your custom agent let me say to to make do doing some kind of research in order to tailor to to I don't know maybe with the right uh amount of output token or input depending on on the on the request but maybe you can create also your own version of the research uh researcher agent or whatever.
Yeah. There's a question in the chat I want to make sure that we bring our attention because it's something that I think we're going to get to but we haven't covered yet about using local models as well and bringing your own key which is something that is supported in VS Code and copilot CLI. So to answer your question and Dinu thank you for asking yes you can bring your own keys you can bring your own model you can use your own local model. Um full transparency I've been experimenting a bit with the copilot CLI and for some of the more agentic things like they do require a high resource model and this it's harder to use the local models it a lot depends on the hardware that you have too but I think the hardnesses itself are not optimized for that yet on VS code you can pick your own key or you can also access the foundry models and if you have models that are deployed within the organizations like the actor you can also use those so just to let you all know that it is supported Um and then there was another question from Marcus.
Should you ask for gravity when gain a response? So would that be part of the instructions I guess to either my agent or my profiler instructions? Like don't tell me the story of your life. Just answer the question. How how can we implement that? Yeah. And there are also models which are more variables and output than others. For example, Opus is very good at reasoning and also very good at telling a lot of things that I mean it depends on the task as always. But if you don't care about much about the instruction the the yeah the explanations tell tell the agent not to to to give them.
Um one thing that I wanted to touch is uh MCP servers. So MCP servers uh let me say are quite bloated in terms of consumption of uh the the context uh window. You can also tell like in VS code there is the chat debug function uh which allows you to I don't know Francisco Franchesco maybe if you have time to open VS code and show it but I mean it's something that tell that shows you how uh your prompt is passed through to the models and uh you can tell how much tokens you are wasting if you are just enabling all the tools that maybe you're not even using uh and if you install some instruction raction some uh extensions in VS Code.
Uh you might uh even have skills and additional agent additional MCP servers that you didn't even knew about and that are passed in each uh in each um request that you make and now you pay them. So it's important to take care of also what you send uh maybe via the science u because that impacts uh quite quite a lot and there is uh well a debate on the internet about MCP versus uh skills with the CLI. Uh essentially um the the proponents of this debate say that it's more efficient to use the skills with MCP with the with CLI rather than using the um the MCP tools because they consume less uh tokens in input uh in in your in your workflow.
I I I tend to agree with this uh with this thing. So I personally disable a lot all the MCP servers that I typically don't need. I just keep very very few um because every every tool costs essentially tokens and if you have many you get maybe like in this example 150,000 tokens just for two definitions which is I would say very bad. So try to reduce them as much as possible. If you need them, use skills. Also remember that also skills are not free because the description and the name are passed uh because the model needs to know that it has some skill.
But still they can be uh cheaper. So don't abuse of to this of the skills also uh just as you shouldn't abuse of of MCP servers. Um yeah uh for the NCP configurations like I know you said you disable a lot of the ones that you use because same thing for for purposes of saving and usage but then you also just share I saw on the screen a JSON file so where you're actually scoping the servers by workplace instead of globally so that they're specific to what your your specific workspace is that yeah that's that's yeah exactly so so instead of installing the global uh uh MCP which you will have every time maybe scope them by by repo um I tend to use this this kind of thing honestly the MCP servers that I use u more or less not even every day it's the context 7 whenever I type some code because I want a fresh library information which maybe the models do not have.
Uh sometimes the GitHub MCP server if I need to to open GitHub on issues. Um and uh the player MCP server which by the way is tool heavy. So if you enable it be aware that I mean you're bringing with you an elephant. So yeah, because depending on the amount of tool that you have at disposal because exactly just to remember for each tool you have you're gonna put into the the input every time the name the description so the LLM knows what the tool can uh can do actually and bring it into when when needed.
So that's why it's important maybe also to think about the NCP server you you you are adding uh how many uh tool you can offer. Yeah and maybe the last things uh that I would like to share then you will add this repo because it's public so you can read it too. Uh but there are a couple of plugins which you can use uh in the CLI. Um one is called cop copilot code act plug-in. Essentially, it collapses many tool calls uh to into a one one program. And this program that you uh that the the LLM actually builds, it's like Python code that runs all these in sequence in one call.
So instead of going back and forth into the calls, you just uh do one single call. The other one is FK RA token killer. Essentially, it's a proxy that you uh set up as a hook and you um you get it invoked every time there is a tool to be called and he knows about 100 uh different uh tool calls which are the typical ones and he knows how to compress them without losing the meaning. So, it's very useful to reduce the number of tokens going back and forth. And I can add on if you're watching this and you're thinking like, okay, well, how do I know how much you like my contacts when they're being in by MCP right now?
Um, at least in the profil commands context that will give you a breakdown mid session. So you can call it using slash contacts and it'll give you like the breakdown of like all the messages, all the free space. I don't think that that's in VS Code yet. There might be a plugin for it, but that's just a good way for you to kind of be aware of what's actually for the context. For the context, I mean management. Yeah. For the for the context. Yeah. On the um insider one, you should be able to see like a ring that it's uh right on the chat.
Yes. If you click on if you click on it, you should be able to compact your your session. So but again let's use the let's use the the suggestion that Marco was saying you need to pick the right moment let me say when you need to switch maybe the the open a new chart so you can start fresh because we we need to also remind that um uh the the context window of the models some some models I mean some models models can can suffer from context poisoning you know so when when you are uh uh having like a long conversation and and then you you're gonna you're gonna talk about something and you start at the end at the beginning of the chat and then maybe uh in the meantime you you're going to talk about other things.
Then the the quality sometimes the quality of the the reply that the model can give you it's like uh a bit less uh in terms of quality because of the long context and the huge context you have. There's also an interesting paper I read about this about a lot of models there. Um the test was like I mentioned and then after 10 or 20 turn I'm going to ask the same question and see how it change or if I get the same result and how the information has changed between all the all the turns I have with the with the model and that's interesting.
So you can see that there's some models also lose up to 40 or 30% of quality in terms of response. Cool. Can you hear me? I see a lot of Yeah, I think you cut off a little bit, but I think we're back. Okay, Franc. I've once again shared the link to the repository so people can go in and also bookmark it. Um, can you show us a little bit of those um, comparativeness? I think you did a lot of testing yourself before you wrote this guide. So, it's grounded on real fact. Um, if there's anything else in the D that we want to cover, we can go through it now.
I think you're you're muted. No, not really. um you might say I mean this is um well no actually there is something if you are managing an enterprise uh so if you're managing an enterprise so it's not like a developer only um you yeah well you you have to set your budget ceilings and you can go very deeply grained into even user level and decide that the user needs to have access to uh some kind of budgets which the others might not. But there is one thing that if you're using GitHub also you might even do as a side effect.
Um you can separate users in different orgs. Uh and in that case you are able to decide which models are using are used by which users. So you can decide that for example users that uh maybe you do not trust uh much you can decide okay let's avoid giving them opus right now because it's very expensive if they uh use it uh maybe in the not in the right way that the price will be skyrocket and maybe you leave it only for some users which are doing maybe a specific job or a specific function of your company.
So you can also tailor this. It's I would say a workaround because it's not uh how the organization should should actually work. But in case you need to limit the number of models available to different uh populations, you can you can do that. Uh but yeah, overall I would say um directed to the output that Franchesco was showing at the beginning of this call. Try to understand who are your top spenders, how they using your models. Try to uh segment users in different categories, understand with them why they were using Opus. Maybe because it was like the shiny tool in town.
But that's that's nice. I mean, but it costs. So you need to compare actually the benefit of using shiny new object versus uh the actual quality that that you get might not be the best. Um so yeah that that's these are my essentially my my suggestions. Yeah for for sure one thing is uh um Andrea you're on mute. Go ahead. Go ahead. I was just saying thank you Mark. Okay, I would say yeah, for sure the first thing uh I would suggest it's like starting from the first of June uh set up your budgets so you you you don't end up with surprises at the end of the month and um and then you can tune up I mean leveraging all the uh feature that we we just released.
I mean we will release with the new uh change about the user level budgets the universal one and single I I mean the at personum and um and then you can um then you can tailor up your configuration to understand better how your user I'm going to ended up consuming your trades the included one and maybe if there's an overage how to handle the overage. Perfect. So, we have a lot of homework. I think um we have some things that we we can do today to start setting up at the enterprise level. Thank you so much for bringing that up for folks to go ahead and and set up those budgets.
That's so important. Um I'm going to share once again the link to the repository on the chat and I will also add it to the notes of the stream. This is done. Um there is a question on where to set up the budgets. Franchesco, I don't know if you have that handy where you could show on the screen the Yeah, let me share back the screen so I can open up uh uh one second here and thank you for the thank you so much for the question. Yeah, take that one out. And of course, this is an ongoing conversation, friends.
If you watch the stream after the live and you have questions yourself like just please post them in the comments. I'll keep an eye on on the stream path post them on the link comments as well. But I think like this this is a very rich resource that Franco Marco and Alen had put together. So let's just put it to use. I'm going to share also the link with the video for walking through how to get your usage what that looks like and then also um a couple checklist that you can start using today. But I'm gonna leave us all with homework.
Almost almost almost run away without homework. All right. So, what are we looking at here? Yeah. Um I mean we can set up to to um answer the question where I can set up the the budgets. Uh you can go in the billing licensing. Here you have budget and alerts. And then you can work here to set set it up you know new budget and then you can decide if you want here you're going to you're going to see right now it's premium request but then it will be bundled um um AI credits you can go here select this configure the new budget and you can you can you can set up different level now you don't see the user level budget but we will be here we can guarantee you uh and then you can select the the user level budget or the organization center or the enterprise.
You can also decide to exclude specific cost centers uh to the um to the uh enterprise uh budget you're going to set. Uh but you need to keep in mind the golden rule is that the um um a user uh developer can stay in only one cost center. So you cannot add the same user in different cost centers. And anyway, once you do that, you can set up the the budget amount. Uh, and when you set it up um and stop usage when and and you leave the tick here, um, what actually happens is that you won't be able to use the chat anymore.
As you were saying before, Andrea, there will be uh also when you reach the limit, you will be able to use the autocomplete and the the the nest next any suggestions, but the chat of course will be unavailable because you have reached the limit. So that I I would be will be so no more uh let me say unlimited usage for for base model because this uh concept would be of course um raised by new uh the new usage building that would be available soon. Okay. So homework to do for all of you enterprise administrators go and set up those usage and thank you so much N did our homework for us here on how to set up those um budget and spending limits.
So that is the workflow just take some time to do it there is a couple of checklists that you can follow. I'm sharing the link to those as well. I think it's very important that you take time even for you and your own individual spending to look at the veil because I was perfectly chocked when I looked at mine and and and the usage of the models like Marco mentioned like why am I always using 4 inex for this like and and you look at because it does identify like what it was used for and a lot of times it it wasn't necessary so I think it's a good idea for you to sort of do that homework on your own so you can understand your own usage then go set up those spending uh limits so that you're not surprises and we're taking advantage of the tool.
Um this is going to take some adjusting for all of us but I'm hopeful like Marco said it's not all gloom and doom. I think it's actually a work that's going to help us work more efficiently in the long run. Um GitHub will continue to provide the top frontier models like we do every time there is a new frontier lab release of a model it will be available to use and you continue to use them. We just got to be more strategic about our usage and quit taking a hammer through everything that needs hammering. Maybe not.
Maybe just needs a gentle push through the wall and not a big hammer. So, I want us all to leave with some homework and think about one thing that we can do today that's going to help us sort of budget better. Um, I'm going to go review my profile instructions because I think I have a lot of bloat in some of them. Um, I threw everything by the kitchen sink and some of my bigger projects. I think that that's an exercise you can point an agent to with a lower reasoning model and just sell it to take as long as it needs and it probably won't spend the time.
So, while we're still not in the usage base filling, take advantage of that allowance that you have now to bust those efficiencies. Um, I shared the links to the repository that turned out so good, Marco. Thank you so much. I know it was a lot of research and work that went into that resource. So take advantage of that. Um I also share the other link. I think it would be great if we can maybe contribute some translations. I've always given people homework to do. So I don't know if you open source it, Marco, but maybe PR is welcome so that we can keep it as a breeding living guide.
So as we adopt into this new way of feeling. Thank you both so very much. Um I learned a lot today and I'm excited to go do my homework. I hope everyone here takes like at least one thing that they can start doing today. Go download your villain, go look at your compiler instructions and just start acting the way that you talk to the models. Um it it's really interesting once you start understanding how it also works you become a lot more budget conscious without even thinking about it because at the end of the day one of the things that you mentioned frank how sometimes you get pollution and the outcomes but it's not it's not even helping for you to add all the bloat in the end.
So, um, thank you all so very much. Thank you both. Thank you for your patience with the noise and and the new background. U, we have to do this again. Let's do it again in a couple of months and see like if we survive or not. I think we all will. We'll make it. We have to survive. Exactly. We have to survive. The idea is not to stop using it. Like, can you imagine like the genie is not going back on the battle, my friends. We just got to be smarter about what we use it and how we're using it.
Marco and Francisco, where can people connect with you on LinkedIn online? Um, we can. Yep. Perfect. Okay. So, and if you are watching this and you are an an administrator of an enterprise, reach out to your sales person so you can understand what credits are coming your way uh and the time allocated for those. Thank you both so much. Have a good rest of your day. Take the rest of the day off. You work already too much. Thank you. Thank you everyone. Bye. Bye. Thank you. Thank you friends for joining this special strength for UAE guide.
Um I encourage you all to please grab those links off the chat. I will post them on the show notes on YouTube as well so that you have them as a resource. This guide that Marco, Olivio, and Alen have put together um and Vesa put together is incredible. There's also a quick links. Please take a look at how to download your user feeling and start working on sort of doing your own housekeeping. Listen, I'm not a fan of it, but I think in the end it's gonna actually this this having to go back and actually take a look at what agents I'm using in my compiling instructions.
I know I'm going to find a lot of bloat there and in the in the theme of efficiency and working better, not just for the usage and the expenditure of it, but to actually set up the models for success. I think it's a good exercise. So, thank you all so very much. I appreciate you all so much for being my assistant. Thank you, Mr. Rus Gun, for actually sharing that workflow. Um, I will also drop in one more time the link to our GitHub checkout that we just did on what it is the auto model select.
Because if you're like me and you've tried it before and you were like, well, this is not actually good. Um, I think you're going to find yourself very surprised. And it's very interesting to understand the thought process and intentionality that it goes behind actually what model is selected. So um I encourage you all to take a look at that as well. Don't forget to like and subscribe this channel and please share the guides, share all the links. Thank you for being here. We'll catch you on tomorrow on Roberto Dog Thursday. Thank you all so much.
Take care.
More from GitHub









Get daily recaps from
GitHub
AI-powered summaries delivered to your inbox. Save hours every week while staying fully informed.