Every Level of a Claude Second Brain Explained
Chapters9
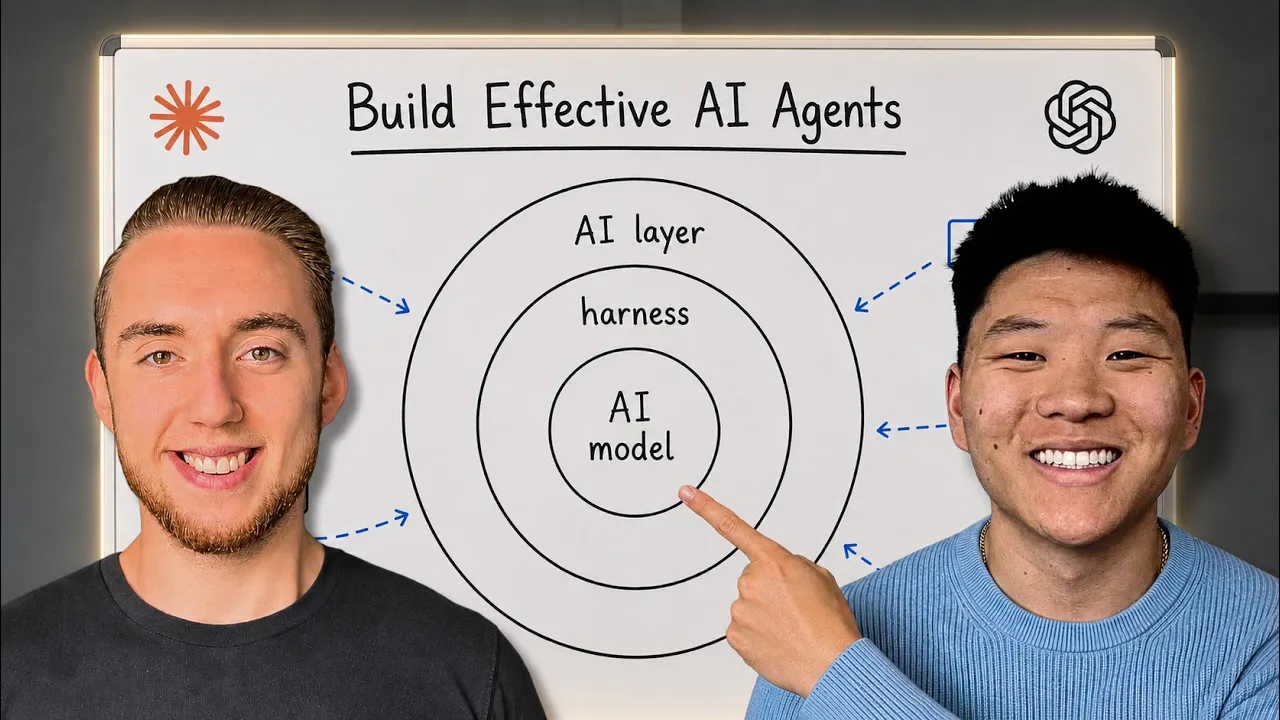
The chapter introduces the concept of building a multi-level AI second brain, illustrating how data relationships evolve from simple, linked files to a full knowledge graph, and discusses why organizing data matters for reliable AI recall. It also sets up the idea of routing, projects, and five levels as a framework for scaling your system.
Five practical levels for building a Claude-powered second brain, from exact-file search to autonomous knowledge graphs and beyond.
Summary
Nate Herk lays out a practical blueprint for constructing a Claude-powered second brain, walking viewers through five incremental levels of complexity. He first demonstrates level one, where a single claw.mmd (or agents.mmd) routes knowledge and lets you find files by exact words, with a simple context folder and a decision log. Moving to level two, Nate introduces a wiki-like layer (the LLM wiki) that groups related documents—such as YouTube transcripts or meeting notes—so it’s easier for the AI to reason over topics and references. In level three, semantic search takes over, showing how vector databases and embeddings enable meaning-based matching rather than exact keyword hits, while highlighting the limitations of chunking and the need to preserve full context for accurate summaries. Level four adds a knowledge graph to map relationships between entities (people, companies, collaborations) and to visualize how data points influence one another, though Nate notes it’s not always necessary for every workflow. Finally, level five points to an autonomous, always-on brain (GBRAIN/GBrain-like setups) that continuously syncs memories and scales with Hermes or other agents, while cautioning about overloading the system with noise. Throughout, Nate emphasizes routing discipline, context evergreen-ness, and the importance of designing for how you will actually use the data in the future, not just how you collect it. He also stresses that no single level is “best”—each project should start simple and evolve to the level that addresses a real pain point. The talk blends practical architecture tips with reflections on privacy, model choice (Claude vs. open-source), and the trade-offs of scaling memory, all anchored in real-world workflows like project management, meeting transcripts, and content production. Folks building an AI operating system or a team-wide second brain will find concrete guidance on file structure, automemory, and cross-tool routing, plus links to the creator’s Free School for deeper learning.
Key Takeaways
- Level 1 uses claw.mmd (or agents.mmd) as a system prompt/router with a simple context folder to route information and enable exact-word search for files.
- Level 2 introduces a wiki-like layer (LLM wiki) that groups related documents (e.g., YouTube transcripts, meeting notes) so the AI can reason about topics and references.
- Level 3 adds semantic search via vector databases and embeddings, enabling meaning-based retrieval, with cautions about chunking and context for accurate summaries.
- Level 4 adds a knowledge graph to map entities and their relationships (e.g., Jordan works at Acme; Acme is endorsed by Postpilot), enriching cross-reference reasoning.
- Level 5 envisions an autonomous, always-on brain (GBrain-like) that continuously syncs memories and can be orchestrated with Hermes or similar agents.
- Routing discipline and a 'start with the end in mind' mindset are crucial: design data architecture around how you will use and recall information.
- The project should be incrementally layered; if there is no pain point at a level, avoid unnecessary complexity and potential inefficiency.
Who Is This For?
Creators and operators building an AI-powered second brain or AI operating system, especially those weighing when to add semantic search, knowledge graphs, or automated memory. Helpful for developers using Claude, Obsidian users integrating with AI, and teams aiming to synchronize data across multiple agents.
Notable Quotes
"Today I'm going to explain the different levels of building your own AI second brain."
—Opening rationale for the five-level framework.
"The true value. Your moat is your data. It's your IP."
—Emphasizes why building a robust second brain matters.
"If you've ever had a point where you ask Claude to do something, and then it asks you, ‘Hey, can you give me more info?’... you probably just didn't give Claude the knowledge to go look there."
—Importance of proper routing and file organization.
"Semantic search is not keyword matching; it's finding meaning and similarity between chunks of data."
—Explains the core advantage of level three.
"Knowledge graphs map relationships between entities and show how they are all related."
—Describes the purpose and value of level four.
Questions This Video Answers
- How do I start building a Claude-based second brain from scratch?
- What is the difference between keyword search and semantic search in a second brain?
- When should I implement a knowledge graph in my AIOS or second brain?
- What are the trade-offs between vector databases and full-text markdown for memory retrieval?
- How can I safely scale my second brain while keeping data private when using Claude?
Claude CodeClaude Second BrainLLM wikisemantic searchvector databasesknowledge graphclaw.mmdmemory.mmdautomemoryHermes agent Interactions with Claude
Full Transcript
Today I'm going to explain the different levels of building your own AI second brain. You can see here we have a visual of three very different types of data. This one is where we have our context really starting to form and we're starting to see some relationships and we're starting to see some different nodes and entities form. And then as we continue to scale this up, add more knowledge, more knowledge, more relationships, we start to get something that looks a little bit more like this where we have clearly different clusters and inside of all of these nodes, we can see how they relate to each other.
And then over here, we're taking all of those relationships a step further, and we're able to then start to see how everything really pieces together rather than just having files that sort of link back to each other. This is relationship mapping. And so really, the idea of an AI second brain has blown up because we're all trying to get as much information out of our heads into our systems as possible. That's the true value. Your moat is your data. It's your IP. But the process of organizing that into a system so that you can use it with a bunch of different AI models and so that it can actually recall things in a way that makes sense rather than just hallucinating or spending a bunch of your time and tokens trying to look through everything.
That's the issue. So clearly all of this is my real data and this is what the actual project looks like. It is my Herku project. I have a bunch of folders and files here and at the end of the day that's basically all it is. It is markdown files that are organized in a way that I understand and that my agents understand. And so yes, I'm going to walk you guys through what I have here and how it works. But I also have this other project where I'm going to show you if you're starting from scratch or if you feel like maybe you're in between level two and three, how we can actually look at the differences and what it might look like to scale up your own systems and start to add context in different ways.
So super excited to dig into this today and I don't want to waste any of your guys' time. So let's just start looking at these five levels and how they differ. All right, so every level of a claude code second brain and I'm going to be obviously kind of referring to cla code a lot, but keep in mind this can be used with any AI model. I use my second brain all the time with codecs as well. I use it with Hermes agent. This can be used by different agent harnesses because it's just files and folders.
So what is the actual job of a second brain? A lot of people probably define this differently, but the way that I think about it is that it's a place for me to save notes, meeting recordings, ClickUp threads, stuff like that. I can save it there, and then it helps me basically ingest it and get it into the right spots so that it can actually find it later. And so that's really the thing to think about is can your agent find it again? and could you find it again? Because if the answer is no, then you probably don't have the right routing or folder architecture set up, which is what I'm here to talk about today.
And one other sort of mindset thing that I want to get out there before we dive into these five levels is that you kind of have to work backwards. You want to reverse engineer based on the question. So, this will start to make more sense as we get into it. But really, what you should be thinking about is how do I want to use this data in the future? Because how it's going to be accessed and recalled determines the way that you put it in in the first place. For example, a basketball hoop and a basketball.
We know what shape the hoop is and we know that the ball needs to go through. So why would we ever design the ball to be a giant square because it just wouldn't fit through the hoop. So that would make no sense. So you need to start with the end in mind a little bit. Once again, I will show you exactly what I mean by that as we continue on. Because remember, we're trying to get to the point where your second brain knows everything about your business, about you, your relationships. It knows everything to the point where it probably can recall stuff better than you can because it has a better memory and it can search through things way faster than you can.
So, we've got five different levels to talk about and they each kind of have different questions. So, level one is, can you find the file or the info by looking for an exact word or name? Level two is, can you pull everything on a certain topic together? Level three is, I searched for different words than I wrote. So, semantic search, you're searching for meaning rather than an exact word match. And then trace relationship chains. Can you ask about topic X? And then trace that all the way back to topic A. And then level five is just kind of making this whole second brain thing super autonomous to the point that you don't even have to think about it.
And by the way, this isn't me saying that number five is best. I have some arguments about why I do not currently sit on level five. The point I'm trying to make here is each level is different and you want to find the simplest level or the lowest level that actually fits your needs. If you don't have a painoint in your system, then I don't really think there's a need to go experiment or develop a new sort of, you know, architecture. If there's not pain, then why create more? Okay, so level one is pretty simple and this is where you always start.
So you start with a claw.mmd or if you're using codeex or something you would start with an agents.mmd but you start with a claw.mmd which is kind of you know that gets loaded up that's almost like the system prompt for that session for that project and then you've just got a bunch of folders and files but the key part there is the claw.mmd is kind of treated as a router. So yes you've got some hey this is your role here is what's important but you also have routing rules. If you ever need to find information about me personally look in this folder.
If you need information about our quarter 1 priorities, look in this folder. Because if you've ever had a point where you ask Claude to do something, and then it asks you, "Hey, can you give me more info? I don't know what you're talking about," but you know there's files and folders in your project. Then you probably just didn't give Claude the knowledge to go look there. It's not just going to go search your entire codebase automatically. I mean, you wouldn't want it to do that cuz it's going to waste your time and your tokens. So, if it doesn't know if something lives somewhere, then it's probably not going to be able to find it.
So, when this is properly set up, you will stop having to reexplain things. you will talk to it and it will just know where to go look and why. But the problems with this is that if it grows too big, it can start to get messy and feel ignored. And this is typically more of like an exact word type of search depending on the way that you route. So if I open up my um example project here, let's open up level one. So in level one, what you can see, pretend this is its own cloud project.
We've got a cloudmd. So let me click into that. We can see here it says this file loads automatically every time you open cloud code in this folder. It is the one file that tells the AI who you are, how you work, and where things live. At level one, this file plus a few folders is your entire second brain. So, here's kind of like that basic knowledge. And then right here, it's this simple where things live in the context folder. Always true background about you and how you work. Read this first projects decision log. And that's basically it.
So, right here, you can see there's a context folder. We have an about me file, which you could grow. We have stack and conversations file. We have decisions. So this is a decision log where you can have your cloudmd always append new decisions and the dates whenever you make a big change to your project or to your life or to your business. And then we have projects. So this is where you could have a markdown file or even folders within the projects for all of your ongoing projects, all of your ongoing clients, whatever it is, however you want to organize it.
That's where you can have some projects. And you can even start to organize these things by dates if you want. So if you want to just have one that's for like May and then you have all of those stuff and you have one for June. The thing that I really want to stress here with level one and the thing that I answer a lot in my community and in the comments is that there is not yet a standard way that has been proven the best way to set up your projects or your second brain besides some of the most common things like your context and your cloudmd and your you know whatnot.
But the point I'm trying to make there is don't see what I do and think that that's the right way or see what someone else you watch does and think that that's the only right way. All that matters is do you have proper routing in place and does it make sense to you and does it make sense to your AI? Okay, so let's say I have my Herku 2 project right here and I need to find something in here but I can't ask AI for some reason. What I need to find is easy because I understand the drill downs.
You know I understand my base folders and let's say I'm looking for the HTML slide deck I built for my ranking cloud code features video. I would come into here and I say okay I know that's a project so I'll go there. Within my projects, I've got another project for YouTube videos. I'll open that up. And now I know I made this video right here, May 30th, Claude Code top 50 features. In here, I have the actual tier list deck. And when I open that up, now I have the slide deck. And not only can I find it easily, but my agent can find it because it all makes sense and I have routing rules.
Real quick, guys, if you're watching this video, you're probably interested in building your own AI operating system. Lucky for you, I have a full free course on that in my Free School community. The link for that is down in the description. Join the Free School community. Hop in here, take the 7-day challenge, build your own AI operating system, and apply these principles into building your second brain, which will make your AI operating system even more powerful. So, links in the description. Let's get back to the video. Awesome. Okay, so that is how you start. Now, as you move up to level two, you might be able to start to work in some things like the LLM wiki, which is what I've got set up for a few different things.
This is the whole Carpathy LLM wiki, which I did make a full video about. If you want to check that out, I'll tag that right up here. But this is when you start to have more files and and they start to take a bit of a different shape and you want to organize them together in a bit of a different way. So it could be really good for researching all on a certain project. It could be really good for, you know, a few of the ones that I've got set up is my YouTube transcripts all live in their own wiki.
I've got all of like my meeting transcripts that live in their own wiki. So for example, this is the obsidian view of my wiki for all of my YouTube video transcripts. You can see here if I go to wiki you can see there's main concepts like aentic workflows AI coding market context window and all of these in here start to relate back to other tools and concepts and videos and stuff like that. So we've got the sources we've got platforms we've got um context management techniques and all of this was autocreated by our cloud code when I told it to ingest this YouTube transcript into our wiki.
So I'm not going to dive super super deep into all this right now but definitely check out that YouTube video I linked. Now, what else is cool about this is this transcript wiki actually lives within my main Herk 2 project. So, here's Herk 2. If I go right here to other worlds and then I go down to YouTube OS and I click into the transcript wiki right here, this is what we were just looking at in Obsidian. We could see the concepts, we could see the comparisons, we could see sources, techniques. This is what we were looking at in Obsidian.
So, all Obsidian is is it basically just visualizes your markdown files. You see here, wiki, concepts, comparisons, techniques. This is what we were just looking at. All we get now is we just get a visual view of all that. And so the reason I wanted to bring that up as well is because I think a lot of people obviously get pretty infatuated by that visual view. And obviously I started the video with that because I think that's what hooks a lot of people in. But all that really matters is can your system grab that and give it to you.
If you are a visual person and you really want that view, then by all means install Obsidian and set it up. It's super easy. But I'm saying that you don't always need that visual layer if it's not beneficial to you. I hardly ever open Obsidian just to be honest because I know that it all lives here and I know that my second brain and my OS can find all of that. So anyways, in level two here, let's look at this. It's very similar in shape to level one. It's just building on top of it because now we have our cloudmd which starts to route to some other things because it routes to the wiki and it still routes to context projects decisions but it's also routing to references and memory.
So we're just starting to add a bit more of these routing rules inside of the claw.md. We can grow the context. We can grow the decisions. We can grow projects and references. And we can also start to get this idea of memory. And what's really cool about this is you can turn on automemory in cloud code. And the AI will basically start to write this file and update it on its own. So you don't even have to think about it. If you come in here and you do /memory, it'll say automemory on or off. And if it's off, if you want to turn that on, just turn it on.
And now one thing to think about is I mentioned earlier that we want to make our second brains tool agnostic. And this is one thing that's pretty specific about cloud code is it uses claw.mmd and it uses this memory.mmd and it keeps that updated on its own. So if you wanted to move this over to codeex, what you would do is you would first of all transition your claw.mmd. You'd make a copy of it called agents.mmd. As you can see here in my herk 2, I've got my if I scroll down cloud.mmd right here and then I've got agents.mmd right here.
And they're essentially the exact same file. Just so codex can read this one and cloud code can read this one. But because cloud code keeps that automemory, all you need to do is make sure you have that memory MD file and just tell codecs, hey, by the way, for memories, look in our memory.mmd file. It's all about the routing there. Anyways, just felt like that was important to throw out. But at a certain point when you have these, you know, wikis, they do start to degrade a little bit because what's what's great about them is that they have indexes, right?
So when your AI starts to look in the wiki, it knows, okay, if the user is asking about agentic workflows, I'm probably going to start here. And then from here, I'm going to drill down and read this to see what else is important to them. Maybe they're asking about the WAT framework, and then I can drill into that. And maybe from there, I need to learn a little bit more about the cloudmd system prompt, and then I will drill into that. So there are relationships here a little bit, but this isn't the same as like semantic relationships or knowledge graph relationships that have more meaning.
This is more about just actually following a trail and reading the page in its entirety. And I'll be fully honest with you guys. I pretty much sit my entire Herk 2 project in this level in level two because this has been working really well for me. Like I mentioned earlier, I haven't felt a pain yet big enough to switch over to level two. And here's what I meant by that. My wiki has links. Isn't that a knowledge graph? Not exactly. Because this doesn't have connections of how they are related. like this is endorsed by this or this has cron to here.
These just have connections because it's like a a C also. It's like backlinks. So, they're very similar and yes, they can achieve a similar effect, but it's still a little bit different. Anyways, let's take a look at level three, which is where you start to do things like semantic search. Whether you do that in Obsidian, whether you do that with Pine Cone or Superbase, however you start to grab the actual semantic search, that is what level three is. And so just as a quick visual for you guys, let's take a look at this quadrant cluster of images.
So every one of these vector points is an image. And what we see in here as the payload is stuff like the file name, the URL, the name of the author or the artist and the URL. But we don't actually see like what's in the image. We don't get a description. So what we have to do is we have to organize these images by meaning or by similarity. So, when I open up this graph and we start to visualize the stuff here, what you see is that we have this main image, these owls, these kind of like I I don't even know.
Um, it's a very trippy style, like hallucenic style. Anyways, then this one is kind of similar, right? It's got those colors. It's got the paint. This one is also similar, but they're not the same. They just share similarities. And as we start to expand these more and more, we can start to get into different styles. So, this one has like some creepy eyes and mushrooms or whatever. This one is kind of more down that fantasy lane. And as we start to build out more of these relationships and meanings, we can expand and grow away from them.
And so quadrant really just gives you a visualization here. I mean, it's a it has clusters and vector store, but the reason I pulled this up as a demo is just because we start to see the actual relationships form here based on meaning. And that's what's important about semantic search is that we're no longer doing keyword matching. We're searching based on meaning. So here in my YouTube transcript second brain if I go to the smart lookup over here this is very different from just the regular search. So for example if I search here for um feedback let's say we're actually doing a match on the word feedback and it's only showing me where that word actually appears inside of our second brain.
But if I come over here in the smart lookup and I search for feedback we are getting matches that have things in here that mean feedback. So live test results, cloud code skills, which was talking about evaluations and stuff. So there's a big difference between keyword matching and semantic search, you know, similarity matching. This one over here is saying X equals X. And this one is saying X is similar to X, Y, and Z. And so this all just goes back to vector databases. I've talked so so much about vector databases, so I'm not going to dive super deep in.
I've got so many resources on my channel, but basically what it is is we take a document, so let's just say YouTube transcript. We chunk it up and then each chunk is ran through an embeddings model. And the embeddings model puts that chunk of text onto like a three-dimensional space where space is related to meaning. And so it decides, okay, this chunk is about a company, so we're going to put it up here. This chunk is about finances, so it's going to go here. And we start to see these vectors form near other similar vectors.
Now, do you guys remember how I said earlier like you want to think about how is the data going to be used? What type of questions are you going to ask? This is a reason why that's so important. So think about this. Let's say I put my meeting transcript of March 5th meeting into my second brain and I put those in as you know vectorized chunks. So let's say when I vectorize that meeting we actually get you know like 20 chunks. It actually creates 20 chunks or however many that is. And then when I say hey Mr.
AI agent can you summarize the meeting on March 5th. It will basically search for March 5th meeting summary and it will pull chunks that are similar to March 5th meeting summary. And then even if it gets the right chunks, it's going to only summarize those five chunks. It's not able to look at the entire meeting summary or sorry like meeting transcript in entirety. So it doesn't really know a summary. It might be missing a lot of key information. Now yes, there are things you can start to play with there like metadata and other things like that to make these results better.
But at the end of the day, people kind of assume that a vector database was some magic solution where it could always pull back what you need. But that is very false. And I mean, think about it like this. Let's say we have a table and we say, "Hey, which week did we have the highest sales?" Okay, the agent looks for highest sales. It maybe grabs this chunk outlined in gray of data and then it looks at, okay, week six here was the highest sales, so that must be the answer. But in reality, you can see week 14 was higher.
Week 19 was higher. So, when you need something that has actual full context, then you can't do the vector database chunking. That's where you'd rather just have a markdown file of March 5th and then all this agent would have to do is read that entire markdown file and then give you a summary and that's just going to be more accurate. So in this project, if we open up level three, you can see it's very similar because you can still have context files, decision files, you can still have all that. And then you might identify, okay, actually this one specific unit of my business, maybe my YouTube transcripts, maybe I want just that to be a vector database, but I still want my context and my projects and my decisions to be marked down files.
So another point I'm trying to make here is just because you have a second brain and just because you have a massive, you know, folder here with a bunch of folders and files doesn't mean that the whole folder needs to be one style. Doesn't mean that everything needs graph rag. Doesn't mean that everything is just LLM wiki. It means that you're able to decide based on the type of data and the way you use it, how can you structure this specific folder in the way you want it. So here we have a vector index folder and we click on the how search works.
It works by chunking, embedding, search, hybrid, reranking. There's some things you can get really, really nitty-gritty on when it comes to semantic search. But what vector retrieval is really, really good at is looking at tons and tons of data, typically just like a lot of text, and when you need a very specific answer, something that's very similar. So, if you had a thousand rules that you needed to store, and you basically said, "Hey, um, can you remind me what rule 17 was?" That might be a really good use case for vector search because it's able to search for rule 17, pull in those chunks, and just give you a little snippet because it would be a waste of time and tokens for your agent to read the entire markdown file of all a thousand rules if you just needed rule 17.
So that's kind of the difference there. Like I said, I've got so many videos on vector stuff on my channel, but really you could say, "Hey, to your cloud code agent, I have this data. Here's how I want to use it. Do you think this would be better for now as markdown files or should I do semantic search?" Like what would actually make more sense here? and it will help walk you through the way that you should actually set that up. So now I hope you guys are starting to understand why I said, you know, moving up on or I'm sorry, like moving up on levels, moving down doesn't necessarily mean better.
It's all about figuring out what is the pain point with what you're currently doing and where would a different level help you out and fix that pain point. Okay, so now let's take a look at level four. This is where we start to get into like knowledge graphs and relationship graphs, which typically are going to be the most complex and sometimes the most expensive as well. If you're doing it on a certain platform, you could always use open source software. But anyways, knowledge graphs. And I also want to be upfront. I've played with these a lot, but I do not actually use these on the day-to-day because I found out just other ways to use routing files and wikis that fit my needs.
Now, my work is very different than what a lot of your guys' work may be. Mine is very project based and it is very, you know, content heavy. I don't have a massive CRM to manage with a bunch of different businesses and clients, you know, and if I did, maybe a knowledge graph would make a lot more sense, and it probably would. But typically, the cool part about that is if you identified that you needed a knowledge graph, let's say for all your projects, you needed you wanted to put all of this in a knowledge graph, the data probably already exists here.
And that's the thing about building out these relationships in your knowledge graph is that the system, whatever software you use, is typically going to be pretty good at embedding that and creating that. But the problem that you have to solve is you have to give it enough data. And so one thing that I really like to do is I like to have these brainstorm sessions as you can see. And what I do with these brainstorm sessions is I use a skill called grill me. So if you see here I have a skill called grill me which I originally got from Matt PCO.
I customized it a little bit. I'll leave the skill for grill me in my free school community. The link for that is down in the description. All you have to do is hop in here, go to classroom, click on all YouTube resources, and you can find all the skills and everything like that. But the skill, what that does is it basically just grills me. It interviews me relentlessly about a certain topic and it creates a brainstorm file here. It only stops when it knows everything about it. So if you wanted to start building up a knowledge graph for all your clients and businesses, just say, "Grill me about client A, grill me about client B, grill me about business A." And it would ask you questions and you can feed it files, you can give it stuff, you can feed it in transcripts, you can feed it in, you know, contracts, whatever it is.
And that's how you can start to form a lot of data. Hey guys, me again. Real quick, I'm editing this video and I realized that I needed to throw out one thing here, which is that obviously if you're putting all of this data and you're sending it all to Enthropic to Claude Models, then that's not private. So, if you feel comfortable with that, that's fine. I am putting a lot of my data in there and it is my business stuff and that's what I'm doing. But if you don't feel comfortable with that or you, you know, don't want to send client data, of course you don't, then maybe you want to do that through open source models and maybe cloud code isn't where you have this second brain that has every single piece of information about you and your business and your client's business.
So the point I'm trying to make here is just this is what I'm doing. I'm obviously aware of the fact that my data goes to Enthropic when I process it through Claude. And if you guys are doing that, then you should also be aware of that. But there are other options if you can't do that. So I had to throw that out there. I am planning to make a ton of videos here soon about local AI and open source models and all this stuff cuz it's a really really exciting space that I think is going to start becoming bigger and bigger.
So yeah, keep that in mind. Back to the video. I think sometimes that's a misconception about how I got here and how people build their own AIOS or second brain is that they think the problem is the system not retrieving it great, which sometimes it is, but sometimes it seems like the bigger problem is getting everything out of your brain into the system. So before you blame AI, take a look at your folders and files and say, is this actually holistic? Is this does this have all the nuance that I have in my brain? Anyways, from there, when you open up level 4, you can see that it's it's, you know, very similar still.
We're just adding on a few things. You can see here we've added an agents.mmd, which is the exact same as the cloud.MD. And what else is cool is you can literally just reference inside of your cloudmd at agents.mmd and then you can delete all this because this basically just like injects that file into here. But I just wanted to show that. But anyways, you can see we're still following the same principles. We have a wiki. We've also added a knowledge graph layer. We've still got the same where things live with the routing with all these just regular folders and boring markdown.
But boring is beautiful. You can see that our memory is still here. It's starting to grow. And we just keep building on top of this. So one thing we added here as you can see was our knowledge graph folder. And so what happens here is we get different entities, right? So like we can see, okay, Jordan is a person, Acme is a company. And then we can start to form relationships between all these things. So Jordan works at Acme. Acme is endorsed by Postpilot. Postpilot is a competitor of Cadently. And it starts to build out not only these entities, but it shows you how they're all related.
And so that's why when I said that I really like using, you know, this um what's it called? LM Wiki is because I have enough of that feel of all these relationships because I've put so much time and effort into ingesting these in the right way and giving it context. The thing about this one is that it has to read every single file it wants. Maybe it was looking at AI video production and all it needed to know was 11 Labs. It still would have read this entire file first. And so that's where sometimes the knowledge graph is actually more lightweight in that sense.
And this is the example I showed at the beginning of the video where we have light rag. And forgive me, I'm going to have to blur some of this stuff out cuz this is like legitimately my entire second brain and our business. But as I really zoom in here, and this kind of slows down my computer cuz there's so much. But what you'll notice is that we actually start to get relationships. I probably shouldn't have done this with so much data, but you can see like we have this collaborates with that. We have this builds that.
And so if I really started to open up all of these little, you know, circles, we could see what was going on and how they're all related. We can see that our 7-day AIS challenge. It was provided from YouTube. It connects to the onboarding process of AIS Plus. It was developed by Aiden. And so we can basically follow around these relationships as you see. And even though it's pretty much the same data that you see here in Obsidian, we're not getting that same level of relationships between these different entities. So anyways, if you guys want to see, you know, a full breakdown video on something like light rag or um graphifier or all the other solutions that there are out there for more of a knowledge graph, relationship graph, then let me know.
But that is kind of the difference there. So if you don't need those sort of relationship chains and you're not worried about that semantic type of relationships, then you probably don't need to use something like a knowledge graph. And then level five, we have more of the always on brain OS and something like Gbrain. Gary Tan, CEO of Y Combinator, he created this thing called GBrain, which pairs really well with GStack. But GBrain is kind of the idea of everything we've talked about here, wikis, routing, relationships, tools. But GBrain has kind of that always element because it is like constantly syncing and refreshing memories and adding more stuff.
So adding in Gbrain to something like a Hermes agent would be really, really good. You could still do it in cloud code, but you'd have to handle those crons and get all that stuff set up, which is why I don't currently run GBandra at the moment, but I have been playing around with it with my Hermes agent. So, anyways, the point here is that it's very similar to everything else we've just talked about. It's just having that auto updating feel, more of the autonomous always on feel. But I will say another thing that I kind of that kind of scares me about that is you have this whole dilemma of, you know, when do you have too much context and when does it get to the point where it's actually doing more damage than it's doing good?
And the reason I bring that up is because I am in complete control of what my second brain ingests. I will run a skill to go grab all of my meeting transfers from the week. I will say, "Hey, here's something. Help me figure out like help me brainstorm about this and then let's ingest it together." And for me, I really like being in that control because in my mind, there's a big difference between a few types of data. If you guys remember in my like AIOS videos, I've talked about the four C's. So, context, connections, capabilities, and cadence.
And for the second brain, I mainly think about it as just these first two. So, context and connections. And so, when I think of context, that's stuff like, you know, what my business has done. So, if I come into here into my my second brain, and you can see here, if I go to um up at OTAAS, so OTAAS are basically just our projects for the quarter. And so here I can see all the Q1 ones, right? I can look at all those and I can click at them and see decisions that we've made in the statuses.
And I can also see Q2 OTAAS. So I can see what's going on here. And my second brain is able to see that because that has been basically those are locked in decisions. This is what we're doing this quarter. And then I'm updating the statuses of that stuff. So that's like context. That's what's going on in the business. But when it comes to connections, if I go back to this, this is more of like the real data that isn't as evergreen. This is stuff that changes. This is like Slack threads. This is emails. this is customer data and that type of data you don't want to ingest into a second brain because that's just noise then then you have to go back every month and like delete old stuff.
So the way that I like to think about my actual second brain is stuff that I'm not going to delete. This is stuff that is like okay in a year will it be good for me to have this memory in here? Yes. Otherwise it's just adding noise. So when you're adding data into your project think about it like the context and connections. think about if this is kind of like more evergreen holistic data or if this is more things that are going to change next week. So, you probably shouldn't pull it in, but you should make sure that your second brain has access to go grab it.
So, that way if I said to my second brain, hey, can you just take a look real quick at what John and I were talking about last week about, you know, OTAA number seven, it would first go to our OTAA file and it would search through there and it it would try to find it there. If it couldn't find it there, it would look through the wiki and it would look through meeting transcripts and see what we talked about there. And if it couldn't find it there, it would finally go to ClickUp itself, pull real data in from me and John's conversations and see if the answer lived there.
And so that in my mind is still a second brain because I'm able to ask a vague question and the second brain knows exactly where to look in what order to find that real-time data and then give me back the answer that I need. That's the question I ask myself is does this thing understand where my data lives and where to look and can it give me accurate answers. So as far as finding your level, remember your whole project doesn't fit into one level. Maybe this folder is level two. Maybe this folder is level four.
or maybe this folder is level three. Here are some things to think about. If you are reexplaining your setup and you need to find things by exact words or files, look at level one. If you have 30 plus notes and you keep forgetting what's in them, look at level two. That's where you sort of like ingest them and get that wiki with relationships. If your project is just completely whiffing on notes that you know exist and your routing isn't working, then maybe you want to look for something more like a semantic search that doesn't rely on an exact wordle match.
If you're looking for relationships and to be able to follow chains of questions and thoughts, then you probably want to look for something like a knowledge graph. And if you're running agents offline and you've got so much data and you want to sync up a bunch of Hermes agents together, then you probably are looking for something like Level Five, something like Gbrain. And another topic that I get some questions about, which I'm not going to fully address in this video, but I will briefly bring up is the fact that you are building your own second brain OS.
So are other people on your team. The next question is how do you actually make sure that everyone's data is syncing together and how do you have more of like your team second brain? There's a lot of different ways to solve that. I think once again it's not an issue of oh do we use Google Drive or notion or GitHub or cloud plugins. I think the issue to figure out with your team is how do we actually make sure that we all habit shift so that this stuff is actually useful and not just noise. How do we make sure that process owners are updating their docs and syncing their stuff there?
How do we make sure that other people are pulling from that rather than always just pinging the same people for questions and answers all the time? I think the adoption and the change management question is the bigger one. The tech and the way it actually functionally rolls out is a little bit less. But what I do know is that you getting set up with your own first and understanding how it works, how you should route, how you should make the decisions of where the data should live, that's the first hurdle. You can only solve the teamwide problem once you feel comfortable about the way you run it every single day and that it works for you.
That is going to do it for today. Like I said, you guys can grab all the skills and everything that you need from this free community. The link for that's down in the description. I will also include the slide deck if you guys are interested in flipping through. So, if you guys enjoyed the video or you learned something new, please give it a like. It helps me out a ton. And as always, I appreciate you guys making it to the end of the video. And I will see you all in the next one. Next.
More from Nate Herk | AI Automation








Get daily recaps from
Nate Herk | AI Automation
AI-powered summaries delivered to your inbox. Save hours every week while staying fully informed.