Your Board Deck Has a Wrong Formula. Excel Won't Flag It.
Chapters13
Discusses shifting from building single Excel/PowerPoint assets to creating an integrated workflow where agents drive entire artifacts, with an emphasis on centralizing agents in the new knowledge-work process for 2026.
Reframe office docs as AI-assisted workflows with a four-stage process to ensure accuracy, not just speed, using tools like Claude, Codeex, and Opus for hostile reviews.
Summary
Nate B. Jones argues that AI can massively boost productivity for Excel and PowerPoint if you treat knowledge work as a centralized workflow, not a collection of prompts. He shares how to build an AI-driven document pipeline with four stages: prepare sources, structure, create, and verify. By organizing source data, producing a clear file spec, and using iterative, hostile reviews (a Ralph loop between Codeex and Claude/Opus), you can produce reliable artifacts at scale. He emphasizes that models tend to be goal-oriented and will produce a deck or spreadsheet when given messy inputs unless you constrain them with a well-defined evidence structure. Jones also contrasts the ease of generating content with the hard requirement of truth, showing how production-grade work demands careful source discipline, validation, and an explicit calculation/checking process. He demonstrates practical stacks: Codeex for creation, Claude Opus 4.7 for aggressive review, and a two-pass rendering strategy for PowerPoint, plus a three-layer approach for Excel models. Finally, he acknowledges that true, repeatable knowledge-work systems require domain-specific setup and won’t be magically button-push simple, but the payoff is meaningful—weeks gained in productivity and higher trust in AI-generated documents."
Key Takeaways
- Organize a structured work packet before asking AI to draft anything: include owners, dates, file types, and a clear inventory of sources.
- Create a formal file specification (narrative spine and slide list for PowerPoint; tab architecture and calculation flow for Excel) to guide artifact construction.
- Use a two-pass PowerPoint workflow: storyboard with claims and evidence first, then render visuals to prevent polished decks from hiding weak arguments.
- Apply a three-layer model for Excel: layer 1 load raw data, layer 2 build calculations/assumptions, layer 3 produce outputs, ensuring recalculation drives correct results.
- Run hostile reviews with paired AI tools (e.g., Opus 4.7 versus a model like 5.x) to enumerate issues before final polish, creating a reliable edit loop (Ralph loop).
- Adopt a tiered task-risk approach: AI is lowest-risk for formatting and draft work, higher-risk for numerical synthesis and regulatory language; tailor verification accordingly.
- Understand that knowledge work is domain-specific and not fully automatable; true productivity comes from building a repeatable, truth-centered workflow around AI tools.
Who Is This For?
Essential viewing for product managers, data teams, and knowledge workers who build executive decks and financial models with AI. It’s especially valuable for teams piloting AI-assisted Office workflows and needing reliability, not just speed.
Notable Quotes
"The key fix is a mental shift. A prompt asks for an output. A workflow defines the stages the output has to pass through before it can be trusted."
—Jones explains the core two-layer distinction between prompt-level output and a reliable workflow.
"Eight documents, 10 documents, whatever it is, you're talking about an order of magnitude increase in productivity on just knowledge work."
—Illustrates the potential impact of a structured AI-enabled workflow.
"The file isn’t done when it opens. It’s done when it has survived a reviewer that looks at it really aggressively."
—Highlights the verification stage as essential to trust.
"I use Codeex to build office artifacts and then I use Claude Opus 4.7 to review them aggressively and generate edit loops."
—Describes the practical host-review loop arrangement.
"Knowledge work is profoundly contingent on domain knowledge."
—Justifies why a push-button generic solution won’t replace deep, contextual setup.
Questions This Video Answers
- How do you set up a four-stage AI workflow for Excel and PowerPoint in 2026?
- What is a hostile reviewer prompt and how can it improve AI-generated business documents?
- Which tools can streamline AI-assisted Office workflows (Codeex, Claude Opus, etc.) and how do they fit together?
- Why is source discipline critical when using AI to produce financial models?
- What is a Ralph loop in AI document production and why does it matter for quality control?
AI in OfficeExcel 2026PowerPoint automationClaude Opus 4.7CodeexHostile reviewer promptsRalph loopSubstack source templatesdata provenancesource discipline
Full Transcript
So, finally, this is the Excel spreadsheet conversation. Finally, we get to talk about what all of these agents have made a difference for when it comes to work and office files because everything still lives in Word. It lives in Excel. It lives in PowerPoint. And when I did all of my prompting guides and everything like that last year, they were hugely popular around Excel and PowerPoint. You can still find them. They're still useful for building individual assets, but we have moved past individual asset territory with what models can do now. It just isn't the same thing.
I I'm not kidding you. I can now draft eight simultaneous documents at once. I don't think that's the ceiling. That's just what I happened to do this week. And I did it by focusing on the structure of the data around the document so that what I got was high high quality and very powerful. You want to think beyond that. You want to think in terms of how you build an entire infrastructure around agents that drives successful artifact creation, whether that's Excel or PowerPoint or something else. And that mindset parallels a lot of what we're seeing in the rest of the workforce as we wrestle with what it means to have agents in production in 2026.
Because the real, you know, n-dimensional move, the big brain move right now is not to think of it as I bolt this onto my workflow, but to think of it as agents are at the heart of the new workflow. I therefore need to torque myself around, change my process, adjust everything inside so that agents are centralized and agents are first. And so a lot of what I'm going to talk about is essentially how you rebuild an office document workflow agentically. And that's the theme. That's what makes this really exciting because if you do that, that's when you get to these massive increases because if you think about it, eight documents, 10 documents, whatever it is, you're talking about an order of magnitude increase in productivity on just knowledge work.
That's huge. And I don't see that happening. In fact, I know that's not happening because I have talked to folks at Hyperscalers about what I'm doing and they're like, "Oh, wow. That's actually really cool. We didn't know that these models could do that." Well, they can. And we're going to show you how. Claude can build Excel and PowerPoint files. Chat GPT analyzes any spreadsheet you drop into it. So does Codeex. Microsoft Copilot for Office hit general availability in April. Everybody watching this video has access to AI that can build a PowerPoint deck in minutes. What you don't have is a way to know that the deck is correct, accurate, and complete.
A and I know this because I've lived it. Last quarter, I opened an Excel file that looked like a financial model. Assumption inputs at the top, revenue projections, valuation outputs rolling up very cleanly. There was a written guide attached saying the model had been validated. And then I opened the revenue growth row and the formula was incorrect and it was copied across every future year from the same two cells year after year. Excel didn't tell me that. There was no ref error. The valuation output still looked good, but it was a financial model in a costume.
It wasn't the real thing. The the layout was right. The labels were right. The cells were incorrect. And that's obviously the only thing that matters. And the same thing is happening in a lot of docs that I see time after time in real production environments. And in this video, I want to fix that for you. I want to get into how we build workflows for agents with agents at the center that help us to build these heavy knowledge work documents in ways that ensure reliability and accuracy. The key fix is a mental shift. A prompt asks for an output.
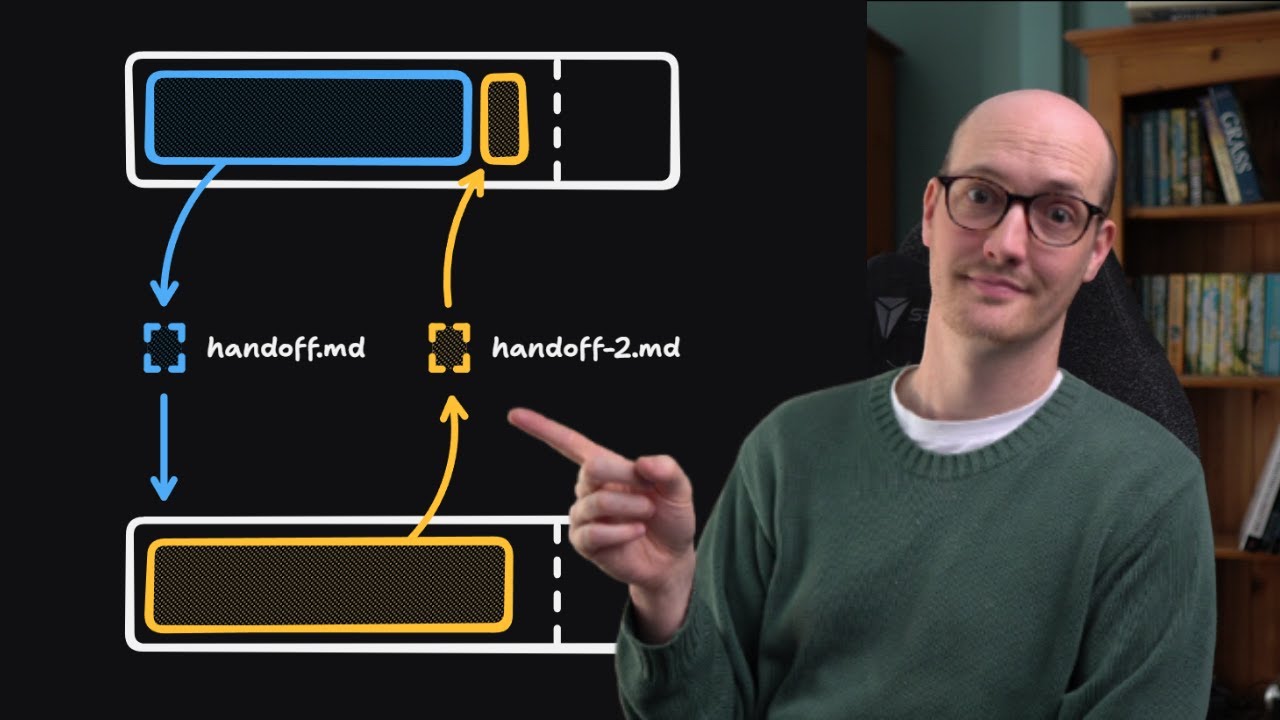
A workflow defines the stages the output has to pass through before it can be trusted. And you need to be in a workflow world, not a prompt world. So for Office files, that workflow has four stages. And we're going to go through all four. One, you have to prepare your sources. You do not ask for the deck or the spreadsheet. You ask for an inventory of what the model has to work with, and you make sure that it's organized. Two, structure. Before any slide or formula gets created, AI needs to produce a file specification. For a deck, that's a narrative spine and a slide list with claim headlines.
For a workbook, it should have a tab architecture and a calculation flow. You want to go from producing that spec to then building the artifact. Right now, you build the artifact constrained by the source packet of information, constrained by the spec that you've built. You're not freestyling from whatever the model thinks the answer should be. And then four, verification. The file isn't done when it opens. It's done when it has survived a reviewer that looks at it really aggressively. I use another model for this. I actually use codeex to build office artifacts and then I use claude opus 4.7 to review them aggressively and generate edit loops.
And it's like my own Ralph loop, right? Where like it finishes and opus looks at it and says, "Oh, you're not finished. Here's your edit loop to make it better." And I just keep running that until I get a very high quality set of docs. And I can run it at scale if my document source repositories are clear. I I'm increasingly thinking of knowledge work as if it was code. So the capability to generate these files is absolutely everywhere and it's far outpacing our ability to scale quality unless we have these kinds of systems like I'm talking about.
I wrote about the upstream piece of this on Substack earlier this month about how to organize your sources before you ever ask AI to write anything. It's critical for this kind of work to actually scale and call that the before, right? This video is the after, how you build with it. Uh, so that link to the previous Substack is in the description. If you're interested, feel free to dive in. I think it's a nice pair with this video. Let's get back to it. The failures I worry about aren't dramatic. They're ordinary enough to survive a quick review.
Right? A board deck pulled from a folder containing a Q3 actuals export and a Q4 plan file. The slide headline says, "Revenue is ahead of plan." and the chart looks really clean and then you look at the underlying numbers and they're blending actuals and plan data because nobody labeled the difference and that error travels every time the deck gets shared. It traveled out of the spreadsheet or wherever it came from originally and it's a problem. So you are now in a world where you can have a great PowerPoint with sharp headlines and executive language but there's no way to show that it has a foundation.
It may look finished but it has no foundation. And I want to talk to you about how you build documents reliably in a pipeline that are wellounded because that's how you actually start to build momentum with this knowledge work. Otherwise, all of this AI tooling becomes a massive trust breaker. And I want to be clear, I'm not cherrypicking edge cases here. Models are goaloriented. If you tell them to build something on a bad foundation, they'll try to do it. And that's the normal result of asking AI to jump straight from messy sources to a finished file.
the model is optimizing for the artifact you asked for. And if you ask for a deck and don't give it choices, it'll try to make a deck. Same thing with a spreadsheet. Unless you explicitly define the evidence structure, the tool treats source discipline as optional. And that's backwards. Source discipline is a big part of the work. And I want to call out this is not because the models are getting worse. In fact, the models have had a lot of work put into them to care about sources. And if you give them the chance to, they will.
Part of why we have to have this conversation now is that the models are trained to check claims and look at sources. And if you don't take the same care as the models do, the models will try to take that care, try to look at sources. And that very goalorientedness to build completely will betray you because you have no clean sources for it to rely on. It will just have to work its way through and guess, but it's been trained to try and find it. So, it will try and do that and it will guess and then you'll be in trouble.
And so we have to be aware of where the hyperscalers are taking the models. And the hyperscalers are basically saying models need to do better work by checking sources. They're right, but we have to do the work of making sure the sources and the workflow pipelines are there so the models can build these office documents appropriately. And that's what serious knowledge work looks like in 2026. The goal is to make every important claim and calculation something that can be checked and that invites that scrutiny. And so you have two stages here, right? You have source prep.
That's stage one. Before you ask AI for the deck or the workbook, you need to ask AI to look at what it can see. What's in the folder? Find out what your work packet has. Does does everything in the work packet have an owner and a date and a file type? And can you create an index of evidence that has all of that? Does it have a status? Has the AI said if it's current data or superseded? If it's an estimate, if it's a transcript, if it's raw data, have you removed sensitive material that would need to be removed before any public-f facing artifact gets generated?
That does happen, too. Uh, have you checked your facts and your estimates based on research on the net? This one move changes the process. A messy folder can become a controlled work packet. The AI can't blend a transcript and a deck and a spreadsheet and a half-remembered assumption into a confident answer if you've organized everything and if there's an index of what's in there. Stage two is structure. Before any file gets created, you need to produce a file specification. At least if you're doing serious work. I'm not saying every single time you have a conversation with Jet GPT.
Don't don't misunderstand me. I'm saying when you're doing serious knowledge work that has implications. So for PowerPoint, that's the narrative in English in a way that you understand. And do insist on plain English. One of the issues with the current models is they like cute language. They like shortorthhand. Insist on plain English. Who is the audience? What decision do they need to make? What do they need to believe before they can make that decision? And then look at the list of slides. What are the claims? What are the supporting source IDs? Where are charts needed?
What are the assumptions? What are the open questions? And for Excel, you need to look at your tab architecture. Where does raw data live in the tab? Where do the assumptions live? Where are calculations performed? Where are checks recorded? Where does the user see the summary and how is it driven? So the file spec is like a blueprint for a serious doc. If the blueprint doesn't explain where the truth lives, the finished file won't do that either. So, if you're wondering how to get started, there is a full source packet template on the Substack, including an ID schema, a status taxonomy, a conflict log format.
If you want to copy it for your team for the next big project you do, I've linked it in the description. Let's move on here, though. I want to talk about file creation. This is the part we all want, right? How can we create this stuff? So only now does AI actually build the artifact. After you prep for PowerPoint, I would do it in two passes. First pass is the storyboard. You want slide titles and claims and evidence and notes. Don't design render yet. No charts laid out, just the argument and the evidence trail. Second pass, render the deck.
This split keeps visual polish from hiding a weak argument. And you catch unsupported claims before they become beautiful and difficult to edit. Right now I am doing all of the argumentation in codec and I'm moving to claude opus 4.7 for the render of the deck because that front-end polish is just beautiful and claude for Excel do it in three layers. Layer one load the raw data exactly. Layer two build the assumptions in the calculation logic and layer three produce the output views. A workbook should be able to answer a very simple question. If I change an assumption, does the relevant output change for the right reason?
And that question matters a lot more than whether the workbook itself looks good. A spreadsheet that cannot recalculate isn't a model. A model whose formulas can't be inspected isn't ready for decisioning. Right now, what I am doing is I am using codeex to build Excel models and then I am having Claude take a pass at making them pretty afterward. But I find that codeex is really really good at completeness in Excel files and that's really important when you're trying to build serious models. One more piece I want to call out here. You need to understand your task risk gradient.
Where is AI highest risk or lowest risk? AI is lowest risk for formatting, layout exploration, chart drafts, summary wording and consistency checks. It's medium risk for source attribution and data extraction. And it's highest risk for numerical synthesis, for financial calculations, for any kind of regulatory language or compliance language, and for claims that will travel up to senior leadership for a decision. Make sure you check those. So yes, let the model help her everywhere. No matter what the task risk gradient is, it's faster with the model. Now, don't give every task the same review burden depending on the risk.
If you want to understand how to dig into that further, there's more on that in the substack. I broke down the full file specification format. There's a PowerPoint narrative spine template. There's an Excel tab architecture. There's assumption log fields. And there are sort of checks, tab, smoke alarms you can set in Excel that I put together. So, if you want the full version both for PowerPoint and Excel, the link is in the description. We're going to move on though to one of the things I think is most important, and that's verification with a hostile reviewer prompt.
So verification asks whether the artifact can be trusted. Sources, dates, formulas, assumptions, charts, and unsupported claims. Every one of these gets inspected. It's a different job from proofreading, and most teams tend to skip it because the file can look done much sooner than it's actually done. The useful pattern is to make the model itself act as a hostile reviewer. You you can use the same model. I use different models for this. I like to play them off against each other. So, I use Opus 4.7 to review what 5.5 does. I think that's super fun. Uh, and I'm going to give you the prompt right here.
So, you know, pay attention. So, the prompt is this. Read this Decker workbook as a skeptical reviewer who suspects every claim and every number. For each slider sheet, identify claims without source attribution, numbers without a data source, charts whose underlying data isn't traceable, formulas inconsistent across parallel rows or columns, and assumptions presented as facts. Produce a written list of every issue found. Don't fix anything, just enumerate. That last instruction, don't fix, just enumerate, is what makes it work. The model is just trying to find the problems. It's not trying to solve them. different task, different output, different value.
A model can catch a lot of its own mistakes when you flip the task from generation to enumeration. And the human gate can stay on the consequential claims, the numbers that travel, the calls that are going to become an important decision. And and one of the things I want to call out here is my personal workflow is very much a Ralph loop for this. I will take a doc that is created by codeex and I will give it to opus 4.7 and I will ask opus 4.7 to do that hostile review and generate an extremely detailed edit list.
I will pipe that back to codeex and I will ask codeex to fix everything in there with a new version in the same folder. Then I will go back to the same thread in open 4.7 and say check the work. Did they do the job? And then I will do it again and I will do it again. And toward the end, I will actually introduce a language check. Opus is actually very very good at checking for LLM isms like you're absolutely right in the doc, right? Something like that. And you can get it into plain English that actually works better for humans to read if you introduce that polish step later.
And the overall goal is that you have an autonomous loop between codeex and opus that gets you to Alevel work without having to invest a ton of time along the way so that your time is best focused on reading A-level material and saying, "Okay, this is where I agree. This is where I disagree. This is where I would edit. Here's some final polish." And that's what it looks like to do heavy knowledge work in 2026. If we step back, AI has made it much easier to create Office files, right? And that matters a lot. PowerPoint and Excel are still where an enormous amount of business judgment becomes visible inside companies.
And traditionally, they have taken real hours out of everyone's week in millions and millions of cases. If AI helps people build those artifacts faster, the productivity upside is real. It's measured in weeks a year for all of us. The upgrade is that you can now build a repeatable production system around the file. Source prep and structure and constrained creation and verification. The file is just an output of that knowledge works system. It's not the whole thing. Drag in the sources, ask for a deck, hope the output is right, that's the version of the workflow that loses you a meeting.
Instead, if you prepare your sources and define your structure and create the file carefully and verify it, you're going to be trusted more and more. So, the next deck you build with AI should not start with a deck. It should start with the moves that I described. Right? Write out a narrative spine before you open the AI tool. Drop in your source materials and ask for a source inventory. Ask for a conflict log before you try and make any slides. Generate the storyboard with claims and notes before any visual rendering. And then run a hostile reviewer prompt before you decide to share it out.
The model can help everywhere, but you have to keep owning the truth. This is the your polish stopped meaning trust. The companies that build a truth layer around their AI office files are going to ship a lot faster and be wrong much less. The ones that don't are going to put out a really nice looking deck next quarter with a number that nobody can defend. And by the way, if you think that's not true, I want you to remember that the team at OpenAI did that with a chart that chat GPT presumably helped make in the chat GPT5 launch.
And the chart was famously wrong and everyone had a good chuckle and that happens to the best of us. We can do better than that. I want to answer one question to close us off and I think I I I think a number of you will ask this and it's simple. Nate, why is it this hard? I have to build this entire effectively knowledge work harness on my own. Why do I have to do that? Why hasn't someone made this for me so it's easier and it's just push a button simple? I have a really clear answer for you.
Knowledge work is profoundly contingent on domain knowledge. That's why it's knowledge work. If you are going to do knowledge work that is specific and memorable and useful and deep, you have to be deep enough in theformational context that you can custom assemble the pieces of information you need to make a useful artifact. It's not something you can generically turn into a workflow. It's not that simple. It's not like you can assume there are five slots for evidence for a PowerPoint deck and good luck if you have more than five. No one who does serious knowledge work thinks like that.
And so I think part of the reason we have to build our own, it's sort of like Luke Skywalker making his own lightsaber. You have to understand how the system works to become a master at that system. And I am sure that there are startups out there that are working on making parts of this simpler, parts of gathering the information simpler, parts of communicating that review step simpler, parts of checking the work and checking sort of the calculations on Excel simpler. All of those pieces are problems that we can get better at solving. But I don't want to lose sight of the fact that good deep knowledge work is tremendously detailed.
reality has a surprising amount of detail. Good deep knowledge work is extremely detailed and it's difficult to generalize an abstraction like an abstracted knowledge work harness over that level of detail. So that's the honest answer for you. That's why we can't just get a push button answer from Microsoft that makes Excel superpowered for this. There you go. I if wishes were fishes, right? I wish it was that way. But instead, we get to work at this. And by the way, for everyone saying we'll lose our brains when we use AI, this is a great example of why you got to keep your brain turned on when you use AI.
More from AI News & Strategy Daily | Nate B Jones









Get daily recaps from
AI News & Strategy Daily | Nate B Jones
AI-powered summaries delivered to your inbox. Save hours every week while staying fully informed.