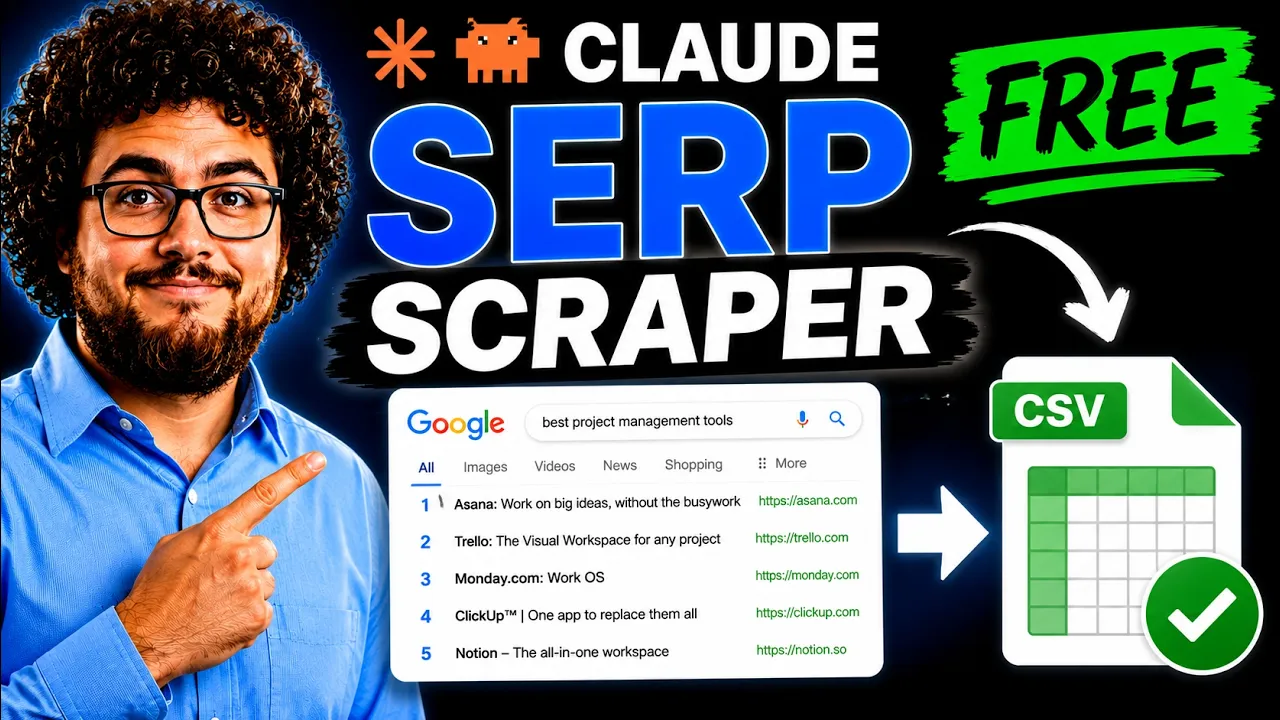
This Scraper + Claude Code = Scrape ANY Website for Your LLM
Chapters9
Highlights how Harbor's web scraping costs are minimal, emphasizing the system can handle large volumes cheaply.
Harbor demos affordable, scalable LLM scraping using Bright Data, turning web pages into structured prompts for Claude and other models to generate blog content and outreach data.
Summary
Income stream surfers presents a hands-on look at building an affordable LLM scraping workflow with Harbor and Bright Data. The host emphasizes that web scraping can be extremely cheap, citing daily runs that rarely exceed a dollar in total cost. He walks through turning raw HTML from web pages into JSON, then feeding that data into Claude or other LLMs to generate blog content, brand profiles, and outreach material. The demo uses Bright Data to bypass Cloudflare blocks and extract rich page data that traditional scrapers struggle to obtain. Key steps include scraping homepage content, converting to HTML or markdown, sending to an LLM for analysis, and then pushing the results to a second LLM to produce final articles. The speaker also compares traditional scraping to LLM-driven approaches, arguing that the latter abstracts away site structure and enables flexible data extraction. Candid recommendations on models—Gemini 3 Flash, GPT-5 Nano—underscore cost-conscious choices for real-time workflows. The video closes with a practical note on setup: proxies, an unlocker API, and a Playground example, plus a plug for Bright Data as sponsor.
Key Takeaways
- Bright Data enables inexpensive, high-volume scraping, with daily costs under $1 even for thousands of pages.
- Harbor scrapes sites behind Cloudflare, converts results to HTML/markdown, then processes them through LLMs for analysis and article generation.
- Gemini 3 Flash offers 1 million context and low cost, making it a preferred model for LLM scraping alongside GPT-5 Nano and other options.
- The workflow involves multiple LLM stages: extract data, analyze with one LLM, then synthesize into a final piece with another LLM.
- Traditional scraping relies on site structure, while LLM scraping leverages prompt-driven data extraction and flexible JSON outputs.
- “This is the output. This is the entire HTML of eyesuit.” (approx)
- “For LLM scraping, the best one would be Gemini 3 Flash. Honestly, this thing is an absolute beast.” (approx)
Who Is This For?
Essential viewing for developers and marketers who want to automate content creation, outreach, and brand profiling using LLMs and advanced scraping tools like Harbor and Bright Data.
Notable Quotes
"This is the output. This is the entire HTML of eyesuit."
—Demonstrates Bright Data’s ability to fetch deeply protected pages and output complete HTML for downstream processing.
"Probably the best one would be Gemini 3 Flash. Honestly, this thing is an absolute beast."
—The creator explicitly endorses Gemini 3 Flash for LLM scraping due to its large context capacity and cost efficiency.
"We turn it into HTML markdown, send it to an LM, get analysis from LLM, and then send to another LLM."
—Outlines the core multi-stage LLM workflow used to transform raw scrape data into publishable content.
Questions This Video Answers
- How can I build a low-cost LLM scraping pipeline with Harbor and Bright Data?
- What is LLM scraping and how does it differ from traditional web scraping?
- Which models are best for cost-efficient LLM-driven data extraction (Gemini 3 Flash, GPT-5 Nano)?
- How do you bypass Cloudflare for web scraping with Bright Data?
- How can I turn scraped data into blog posts or outreach emails using LLMs?
Web ScrapingLLM ScrapingHarborBright DataClaudeGemini 3 FlashGPT-5 NanoCloudflare BypassOutreach AutomationContent Generation
Full Transcript
So just look at the cost of this guys. It basically costs absolutely nothing to power the entire web scraping system inside Harbor. Now for context guys, Harbor probably scrapes thousands and thousands of web pages every single day. And the maximum cost we've actually had is 88 cents here, 96 cents here. And this is for a lot, and I mean a lot of scraping. So, a lot of people think that this stuff is expensive. I'm trying to show you guys that it's not expensive and that Bright Data is the number one provider for web scraping. Let's jump into things.
Okay, so what exactly is LLM scraping and why is it so important? Now, you may be familiar with LLM scraping because you've used Claude code or maybe chat GPT and you've asked it a specific question and what it will do is it will take your question and it will search the internet for you. But what we want to do is have our own system for LLM scraping so that we can get data from a web page, turn it into HTML or markdown, send it to an LLM, get the analysis from the LLM, and then send it to another LLM to do something with that analysis.
Okay, so let's see a little example here from Brite Data. So if you go on proxies and scraping and then go to playground and then just copy this right here, right? Target URL and then just run the curl request. What it does is it gives you the raw HTML output of this entire website, right? So this is two men. This is a website that is normally or I'll give you a better example. Let's do eyesuit. This is normally behind a cloudflare wall which means you cannot scrape it. But with bright data you are able to scrape it.
Okay. So let's watch this happen in real time. There we go. It then scraped this. This is the output. This is the entire HTML of eyesuit. Right? So this might not seem that useful but there are use cases for this. So if you take this entire output and let's for example go to Claude. So claude.ai. And what we can do is we can build a JSON request here. So please give me a JSON output for this website I need. So let's say images, pricing, products, uh what else could we do? Let's say branding, logo, images, and then let's just say and anything else relevant you can think of for writing a blog.
And then we just paste the entire output. And then what this will do is, and I recommend a cheap model for this, by the way, guys, if you're going to do LLM scraping, let me just show you a couple of models, which I personally would recommend. So, probably the best one would be Gemini 3 Flash. Honestly, this thing is an absolute beast. It has 1 million context and it's extremely cheap. Another model is GPT 5 Nano. These are all of the models that I personally use inside Harbor, right? So for LLM scraping, GBC5 Nano is another one of the best.
I have to say, you don't want to be using Sonic for this kind of stuff because it will just cost so much money. You could use Haiku, but yeah, Haiku is just not up to scratch unfortunately. Probably my number one model is Gemini 3 Flash. Um, and yeah, I would use this. You can use this with an open router backup as well. So if your primary Gemini account fails for whatever reason, it will also try with this. So look, this is what you get and this is where it starts to get interesting. So site name, full name, URL, description, tagline, company, VAT number, address, currency, language, branding, right?
And you can literally go and open this and then you can have a look at this. There it is. Bang. So look, phone number, social, featured products, all of this amazing information that you can use for whatever you want, right? So if you wanted to, you could use this for creating a brand profile inside your SAS business. You could use this for outreach, right? So you can start to out reach out to these people. Um, so you can say, "Look, uh, we need their email as well." I'm guessing that it will have got their email somewhere.
I'm sure it did. and all of this amazing information that you can use for whatever you want. This is LLM scraping. Taking a large website piece of information and turning it into something that an LLM can digest, right? So you press copy here and you could say now make me a brand profile for this business for example. Right? So we have phones here, everything. We have their Instagram. You could then you know do whatever you want. The next stage of this could be okay look at their Instagram and see if their Instagram is active. If you're a social media company, right, for example.
So what we do is we do a homepage scrape just like this, right? This is an example from Harbor. So let's just show you guys what we do. So we turn it into HTML markdown, send it to an LM, get analysis from LLM, and then send to another LLM. Right? So here when we send to another LLM, what we say is we say like take all of this information and write an article with it, right? So we don't just scrape one page. Obviously we scrape several pages with Harbor um just because that's how things need to happen when you're writing a blog for someone.
So we might scrape all of these pages here. So these secondary pages, if you look, it came out with these um brands, right? So you can do this on repeat. You look for people's brands. Once you find their brands, you scrape each of these individually. Right? So it's the same thing literally. All you would do is just change this link here for this link and then press enter. And then what this is going to do is it's going to scrape the kiton page. Right? So again, we could just let I just do a clear and then run that again.
And I can do arr c and I can say now extract all of the images from the kiton page. Right? So let's just do that. So now I'm going to say please please now extract all the commercial intent information from this page and put it in a digestible format for me in JSON. Right? And then just paste this. What this is going to do now is it's going to go through. Okay. Okay, so I had to start a new conversation just because of the way context limits work. Okay, so context size exceeds the limit still.
So look guys, this is actually a Cloudflare website. So if you try and scrape this with basically any other web scraper, it will not work. Only with Bright Data will this actually work. So let me just I want to I want to do this on this link. By the way, guys, this video is sponsored by Bright Data. Go and check out Bright Data. They are really really good. We use them every single day as you can see. Like it I don't normally take sponsors unless I'm using the product myself. Like we've made 5,000 requests to Bright Data recently, 179 megabytes on the 7th of April.
This is our main scraping tool for Harbor and also for Grove. There's a link in the description of the video. There's always a link in all of the videos that I make. Go and check them out, guys. Go and get some free credits from Bright Data. And thank you very much to Bright Data for sponsoring this video. So yeah, guys, if you're planning on making your own kind of blog writer or outreacher or basically anything, right, then you're going to need bright data in your arsenal. It is one of the best ways to write an article or to get information online.
A lot of things are behind Cloudflare, right? So you can see this is just a much more refined approach to this. So yeah, this is a great example of the information that you can get out of a web page that you might not expect that can be used to then write an article. Now the really amazing thing is this JSON can be anything, right? This is why LLM scraping is so damn important. When you compare it to traditional scraping, the way traditional scraping works is you need to know the structure of a website. you need to scrape it and then you need to extract each piece of information from the known divs or image links or whatever it is.
LLM scraping works in a completely different way. So now if I press copy here and let's just go to chatbt and let's say write me an amazing fantastic article in markdown using this information that will rank on Google. Obviously, you need a much better prompt than this, but this is just a quick example. So, I'm just going to paste this. What it'll do is it will use this information to now write an article, right? So, this is the beauty of this. This is basically how Harbor works at a very, very base level, right? But it does work.
It's a little bit more complicated than what I've just shown you in this video. There's a lot more to it, but yeah, at a very, very basic level, this is exactly how Harbor works. People find this stuff useful, guys. A lot of people don't know how to do this kind of stuff. So, if I just go down to mark down to HTML and show you the final result here. Here we go. So, this is the final article. Bang, bang, bang. You can see really, really nice. It's got all the links and everything. And this is how you make this kind of content.
Right now, this is just one example that you can use bright data for. But overall, Bright Data is one of the best scrapers on the market. We use it every single day. and they're also an amazing sponsor of the channel. Go and show them some love, guys, from me. Go and use my link in the description and in the pin comment. You can get started pretty bloody easily. There's a quick start for developers. You have MCP as well if you want to use this inside Clawed Code or inside your systems, right? We don't actually use MCP.
We just use the API because I find it easier. But definitely go and check them out. All you do guys, proxies and scraping right here. Make sure that you have a unlocker API or web unlocker. This is what we use. You don't have to use this, but we use the unlocker API. So, just create a zone here. Make sure you create the zone, etc. Get all that information. And then if you just go to playground and then just grab this code here for example, this will actually give you everything you need to then go and build a system like the one I showed you today and like the one that we use inside Harbor that is doing so well for us.
Thank you to Bright Data for being such an amazing sponsor of the channel, guys. Go and check them out. Go and use my link. Thank you so much for watching. If you are watching all the way to the end of the video, you're an absolute legend and I'll see you very, very soon with some more content. Peace out.
More from Income stream surfers








Get daily recaps from
Income stream surfers
AI-powered summaries delivered to your inbox. Save hours every week while staying fully informed.