Bash is bad for agents
Chapters8
Argues that relying on Bash for AI agents is limited and introduces the need for more capable execution layers.
Bash is a stepping stone, not the endgame for AI agents—we need typed, safe, code-aware environments like TypeScript execution to actually scale agent capabilities.
Summary
Theo (t3.gg) argues that while Bash has been the backbone of earlier AI agents, it isn’t enough for robust, scalable tooling. He compares old methods— dumping large codebases into prompts and fragile repo-mix workflows—unfavorably with tool calls and code-driven context retrieval. The talk weaves through tokenization, context windows, and the dangers of bloated context when feeding entire repos to models. Theo showcases why determinism improves when agents issue small, targeted commands (GP calls) rather than shoveling gigabytes of code into prompts. He highlights newer approaches like TypeScript/JavaScript-based execution layers (Just JS, Exeutor concepts, Rivet, Sandbox) and portable, typed environments that can be shared across teams. The message is clear: Bash is useful, but we need safer, more scalable execution layers and tooling to realize truly capable AI agents. The video also touches on practical demos and sponsorships, underscoring the current state and imminent directions of agent tooling in 2024-2025.
Key Takeaways
- Large codebases in prompts drastically inflate token load, slow responses, and degrade accuracy; targeted 5–15 token GP commands to fetch context dramatically improves results.
- Tokenization has evolved to represent programming language structure more efficiently, reducing context size without losing essential information.
- Relying on repo-mix or dumping whole codebases into prompts is costly and counterproductive due to token overhead and memory constraints.
- Deterministic tool calls (via GP commands) outperform pure model memory when fetching code context, enabling repeatable results across runs.
- A purely Bash-centric execution layer is insufficient for real-world governance, approvals, and multi-tool orchestration; standardized, safe, and auditable environments are needed.
- TypeScript/JavaScript-based execution environments (Just JS, Exeutor concepts) offer safer, isolated, and portable runtimes that can run code without exposing user files to all agents.
- Code-driven tool discovery (SDKs for MCPs, code-as-tools) reduces context bloat, improves latency, and increases reliability compared to raw MCP dialogs or massive context dumps.
Who Is This For?
Software engineers and AI practitioners building code-writing agents or CI/CD automation. Essential viewing for teams exploring scalable, safe execution layers beyond Bash to power robust AI-assisted development.
Notable Quotes
"“Bash is not enough.”"
—Theo stakes out the central claim of the talk—Bash alone can’t meet the needs of modern AI agents.
"“This is just one of the many things we have to do to get to a future where the AI tools we love can do more with our systems than we can today.”"
—Emphasizes that Bash is a stepping stone toward more capable execution environments.
"“You can do basically anything you need to on your computer using Bash. Or can you?”"
—Sets up the problem that Bash, while powerful, is not sufficient for scalable agent workflows.
"“If you dump the entire codebase into context, you’re drowning the model in tokens.”"
—Critiques context-hungry approaches and motivates compact, code-driven context retrieval.
"“TypeScript is right there… portable environments that can be shared with teams.”"
—Highlights the opportunity for typed, portable environments over raw Bash.
Questions This Video Answers
- How can I replace Bash with safer, typed environments for AI agents?
- What are Just JS and Exeutor, and why do they matter for running AI tools in isolation?
- Why is token management important when building code-calling agents?
- What are best practices for tool discovery and code-driven context retrieval in AI agents?
- How can TypeScript-based environments improve collaboration and governance for AI tooling?
Full Transcript
Back in my day, the kids used to have to ask chat GPT what things it should run in their codebase and then they would copy paste over the commands to run in their terminal themselves. If they wanted the model to know about their codebase, they would use all sorts of weird crappy tools to try and compress the entire codebase into data that they could then hand to the model with these giant prompts that just never really did anything right. Obviously, that's not how we use AI nowadays. Everyone's using tools like Cursor, Claude Code, the Codex CLI, T3 code, and more where the models can actually use your system.
And by your system, what we usually mean is bash. These models are given access to tools that allow them to call bash commands in order to do things on your machine like read some code, ideally just small amounts and not everything where it floods your whole context in order to do the right thing and then actually apply changes to your codebase, run commands, pull packages, and all the other things you need to do. Because as we all know, you can do basically anything you need to on your computer using bash. Or can you? I'm here to drop a pretty hot take.
Bash is not enough. As crazy as it is, these models can do so many powerful things on our machines by running commands, that's not the ideal way for these agents to run. It is a really important stepping stone. But today, I want to emphasize just how much it is a stepping stone. It is just one of the many things we have to do to get to a future where the AI tools we love can do more with our systems than we can today. This one's going to be a bit of a technical deep dive going into how these models work, what's changed with how our agents and harnesses run over time, and most importantly, what do future solutions look like?
I'm very excited to dive into this, especially as I've been in the weeds thinking about these things myself with T3 Code a lot recently. But as you guys know, T3 Code is open source, which means that we're not making any money on it. So, we're going to do a quick break from something that does pay me, today's sponsor. Today's sponsor is browser based, the best way for your agents to use the web. Historically, I haven't been that interested in things like this, but now that GPT 5.4 is here, my tune has changed entirely. I'm just going to give a quick demo of something that was not even kind of possible before, but now absolutely is.
This is an app that Ben built for testing and comparing the difference between the browser use method of agents using the browser and this new JavaScript-based method that exists for GPT 5.4 cuz it was specifically trained on this type of pattern. What that means is the agent can write code and execute it in the browser itself. Instead of having to manually select and click something, it can write a line of code to do that instead. And it's way more efficient. Currently, the demo app is using Google Flights to try and find flight options, but I'm going to change this entirely.
Here, I'm telling it to go to the Wordle page and play. We'll see how it does. Thankfully, with browser base, you can actually open up the session and watch as it happens and even watch the replay after. And here we can see the model playing the game. And if we go back to our terminal, we can see what it's doing here in the code that it's writing. And now it is starting to guess. And it is doing that by writing JavaScript code that it executes to change the word in the Wordle instance after reading the code on the page and figuring out how it works.
It did just run the same guess twice, which means it's far from perfect, but I think it has a good chance at still getting it. Fingers crossed. Let's see how the agent does. And look at that. On the last guess, it was successful. So, if you're looking for help cheating on Wordle or doing anything else that is that type of complex web interaction, look no further than soy. Browserbase. When I write down some bold text like bash is not enough, I definitely need to justify it. But in order to do that, we're going to have to start a little bit earlier.
We have to think a bit about what can LMS even do? Well, there's one thing we all know LMS can do. They can generate text. And the way things started back in the day when we wanted to try and make these models more capable, specifically generating code type text, is we needed a way for the models to know enough about the code to make good decisions. models have a thing called a context window. It's how many tokens can fit into the model when you're trying to get it to respond with something. In the end, all these models are is really, really effective autocomplete where based on the things that have been said so far in the chat history, what does it think is most likely to be next based on all of the information it was trained on, all of the reinforcement they did after, and all these other things.
The parameters inside the model are effectively just vectors pointing to and from different things based on what came in the past. So, it applies all of the data that you send so far and uses that to point in a different direction on what it thinks is the most likely next chunk of text and it does this on repeat constantly until eventually hitting an end signal where it decides it is done and here is your result. In order for the models to be able to do this type of autocomplete generation, they need to have a way to break up the existing text in order to parameterize it, pass it to the model, and get the next tokens out.
A token is just a group of text usually small number of characters like one word or just three to five cares. So if we copy paste this for example this blurb on the open AAI tokenization demo paste it you will see below here that this text is 280 characters and it's 52 tokens. The first word open AAI apostrophe s there are three tokens open AI and apostrophe s. Then the next word large isn't just the word the space is included and language also includes the space. What's even more interesting is how these tokenization processes have changed over time.
If we go back to the GPT3 tokenizer, very interestingly with this paragraph, switching from the old and the new tokenizer doesn't seem to do anything. But if we hop into, I don't know, some code like here, let's grab this section out of my codebase, we'll see that for code, this is tokenized down to 306 tokens. And the tokens are all things that make sense like the start tag is its own token. Class is its own token. The equals in the start of the class name is its own token. And then the colon quote at the end here is its own token to signify like the end of these things.
It makes sense if you compare this to how tokenization used to work with GPT3. It is broken up significantly more. Including each of the spaces at the start here being its own token. And remember each of these tokens is effectively creating a path. Like these are directions that you're giving the model to drive somewhere. This is like saying drive 10 feet forward, then drive 10 feet forward, then drive 10 feet forward over and over again when it's broken up this way. What you really want to do is say drive until you hit the class. And the new tokenization methods have done this and made it a lot better to get the data to the model so that it has fewer tokens as it's trying to find the path where it wants to go.
All of these are things that the labs have put a ton of effort into. But an important thing to understand is that your chat history is full of these tokens. And the tokens in your history are what determine what tokens are most likely to be next. So if your tokens are in Spanish, the next token is most likely to also be in Spanish. If your tokens are in JavaScript, then it's most likely to generate JavaScript. The history of your chat is very much important in determining what the outputs are. So if you want the model to output code that is like your code in your codebase, you should just throw your whole codebase in the context.
Right? Right. No. The problem is if your prompt is I don't know, help me make this new feature work. This is only eight tokens and if you paste your codebase in like let's just take this normalsized file. This is 155 line file very small. That's 1,200 tokens already. So my prompt is eight tokens and one file in my codebase is 1,200 tokens. If I put my whole codebase, we're probably going to get close to the limit of how many tokens the models can even handle. Most are between 100k and 250k, but they get way dumber as you get closer to the end because all of those tokens make them worse at doing the math to predict what's next.
This is why I genuinely detest tools like repo mix. This tool has probably cost my company over six digits. We're at least $100,000 of wasted money in because of this tool. Because when we still priced T3 chat based on the number of messages and not how expensive your messages were, people would grab their codebase, dump the entire thing into a 100,000 plus token file, paste that into their editor, or in this case into T3 chat and use it to try and get code being generated for cheap by using T3 chat as an alternative to cursor.
No. Bad, dumb. Don't do this. Not only is this going to cost way more because you are charged based on how many tokens go in and out, this also means you're going to get way worse responses because the history is now full of [ __ ] you don't actually want. When I'm trying to make a small change in one file on the TypeScript package for my monor repo, it does not need to know about every line of code of Rust in the codebase. This way of getting context to the models is not just bad, it is expensive, slow, destructive, and hurts the quality of the output.
If I ran Repo Mix, I would put a little warning at the top of the page saying, "Hey, we've learned this is the worst possible way to ever code with AI, and we recommend you do literally anything else because we have now learned as an industry, this ain't it. This is bad." So, what does work? Bash does. I know contradictory. This video is bash is not enough, but but hear me out. If the problem is that the model needs to know what needs to be changed, giving the model every line of code in the codebase doesn't make sense, we need to think back a bit to how we work.
Do you actually know where everything in your codebase is? If so, congrats. I hope you get a real job soon. For those of us who work in real code bases with real co-workers, nobody knows where everything is. That is not realistic or viable or even sane. You can't know where everything is in your codebase. So, what do you do when you need to make a change? you probably have some signals or some system in your head on how you get the place you want to be. If there's a button on the site that is the wrong color, I can grab the copy and command F4 in the codebase to find it.
Or maybe I can look at the class names that the button uses and try to find those. Or I can bring in some dev tool that will let me go straight to the file from the web app directly. But I need ways to get to the right place because reading my whole codebase line by line is not a productive way to solve anything. It is also worth noting that models have to start from scratch whenever you make a new chat because they don't have memory the way we do. They don't remember where things are in the codebase.
And even if they did, they'd probably be bad because if those things change, it would get confused and do things wrong. So, how do we replicate this with the models? How do we make it so the model can bring in just what it needs to know and not everything else? The reality is that we can't. There's no way for us to guarantee the models will not have useless context some amount inside of the chat history. But we can make them less likely if we let them use the thing they can do, which is generating text to find the text they actually want, which is the pieces of code that are relevant.
And as we've all seen from watching Primagen streams and other terminal wizards that are big Vim people and use Rip Grep really well and all that, you can do a lot on your computer using a terminal. You can do pretty much everything you need to do on your computer using a terminal. So tools like cloud code started to happen and they allowed the models to write commands to find the things they didn't know about or they couldn't use. So instead of giving the model the whole codebase and telling it to find the right file and make a change based on this gigantic pile of stuff it has remember nondeterminism machine.
So all of these parameters are non-deterministically pointing to different phrases, different keywords, different like parameters. As you add way more data in the likelihood it steers you the right way inherently goes down. But if the context exists in the codebase and you write a GP command to find it, GP is deterministic. It will find the same things every single time. So as long as the model can write the correct five to 15 token command to go get the right context, it is effectively deterministic. A way to think of this as a range of deterministic behavior.
You have fully deterministic on one side and you have straight up random on the other side. And this is kind of the problem with AI. AI is super non-deterministic. When you hit generate on a model, it's going to do its best to generate something that satisfies whatever it was asked about, but it isn't going to do it the same way every time. If you ask the same model the same question three times, you'll get three mostly similar answers probably, but they'll be meaningfully different. So, just to spectrum this, math.random, the JavaScript function, is not fully random, but it's pretty goddamn close.
And console.log, log hello world is deterministic because every time you run this it'll run in roughly the same amount of time and give you the same answer of hello world. AI doesn't really end up on this deterministic side a whole lot. But do you know what makes it very quick to move the other direction? More tokens. More tokens effectively equals more random. As more tokens of context are given to the model and more tokens are generated by the model and more things have to be gotten around, the likelihood it gets it right goes down. to analogize this to how humans work.
If you have a desk with three things on it and I ask you to describe where the three things are, you'll probably do an okay job if you look at it and then I ask you the question and you can't go back and look. I just you're just going from memory like what is where on the desk? You're much more likely to get it right. But if there are 300 things on the desk, how likely are you to be able to remember even three of them? Probably not very likely. Models are working effectively the same way.
And once the model sends a message, it's now part of the history. It's now part of that pile of tokens that it has to traverse. And we want to keep that pile small in order to make it more likely we get the answers we want. So how can we keep the pile of tokens smaller? Well, if the previous solution was to dump the whole codebase, that's not going to keep anything very small. Like let's say instead of dumping the codebase, we write some simple GP command that's just seven tokens and it grabs eight lines of code from one file that are another 30 tokens.
We've used under 40 tokens to get the information the model needs instead of handing it 100,000 tokens and hoping it finds the information they need. This is a magical improvement that has been a huge part of why the models have gotten so much better at coding. And there are certain labs that just haven't caught up with this reality that it's better for the model to know how to find the context it needs rather than for the model to traverse the context that it already has in the history. This is part of why the Google models are still as bad as they are because Google made their models really good at retrieving data from large amounts of context.
OpenAI and Anthropic as well as all the Chinese labs are focused more on the tool calling characteristics that allow for the models to go get the information that they need when they need it rather than to have it all provided up front just to confuse it more. So now we need to get to the topic of the video. As I mentioned before, as great as Bash is as a thing the models can use to collect this context because you can operate Bash with text, the models can generate text, train the model to do this, and the model will now be able to get the info it needs to do its job.
So what isn't good enough about this? There are a ton of layers here from trying to command UIs like clicking buttons in the browser to having a safe place to execute the bash code so it can't accidentally pone you delete things it shouldn't or do things on your system that you wouldn't want it to trying to find a way to do this that doesn't require every single agent to have its own dedicated machine to do things on. How can we virtualize this more or maybe put it in the cloud or maybe put in the browser?
How do we let these methods of work getting done be more accessible outside of having a dedicated VM for every box? And also, Bash isn't necessarily much of a programming language. I mean, it works. It's good. You can write a lot of really powerful scripts with it, but we need to be able to do more than you can with Bash. And I'm sure we've all seen this at some point. Something I noticed early with my testing of GPT 5.3 codecs was that the model really liked to write Pearl scripts to edit files on my computer.
Instead of manually calling the edit tool or doing the edit in some other way, it would write a small Pearl script and then execute that as a command to make those changes. So, what can we do better? I have some solutions in mind, but first I want to show you another solution. Today's sponsor, I'm going to do today's ad a little bit differently. I just want to show you something. Do you see this? This is CI that failed telling you why it thinks it failed. Think about that for a second. Do you understand how far that is from the GitHub experience?
When I use GitHub and an action fails, I have that weird tingling feeling inside that I'm going to have to go spend 20 minutes to multiple days playing whack-a-ole trying to figure out why the thing doesn't work on GitHub, but works totally fine on my machine. Probably should have mentioned this a few seconds ago, but today's sponsor is depot. They make your GitHub actions and Docker builds way faster. But now you don't have to use GitHub actions anymore because it turns out, as you probably know, GitHub actions kind of suck. And that's why decided to make their own alternative.
And damn, it's incredible. It kind of shows just how bad GitHub actions are that they were able to build their own as a small team and just crush them in every single way. It's also worth noting that all of this stuff is agent ready. And I don't mean some crappy MCP server that's super unreliable. I mean a CLI that lets you get all of the information about your actual actions as they run, as well as the ability to run them directly yourself. I mean, the ability to properly debug and monitor your jobs, getting all the info you need, and even the ability to SSH into the box when things are happening.
You can even run an action with local files without having to commit. Do you know how useful that is for agents in the loop? They could charge more than GitHub for this, but they're not. They're actually charging comically less at 0.01 01 cents per second of runtime. If you're still using GitHub actions, you're wasting your time. Fix that now at soyb.link/devo. So, in order to talk about why bash isn't enough, we need to talk about where the bash happens. It's the execution layer. It's as the model is making tool calls, making decisions, looking for information, doing things, and collecting things.
Bash is used not just for collecting context, but also for applying changes, for confirming changes, for shipping, for doing so many more things. And that execution layer that it does those things in is one of the areas that is the most up for grabs right now because ideally we won't all just be running these things on our computers indefinitely. Reese wrote this little piece on the execution layer. I think it's a really good place for us to start here. LMS are in desperate need of an execution layer made for them to run tool calls in.
A year ago, LM were making direct calls to tools. We found that it flooded their contacts with irrelevant information to them and found incredibly poor performance. Then we discovered that with coding agents, when you give them less tools, they perform much better. And now every agent has a bash tool because a bash tool is just one tool. And again, remember, flooding context is the worst thing you can do. I got a DM a few days ago from somebody who noticed a weird thing when they asked a question to Gemini 3 Flash on T3 chat about cooking or something.
And it ended the response with, "Knowing that you're a developer, this will be the most interesting to you." And that was like half the response. And they hit me up confused like, "Is this a problem with T3 chat? Why is it talking about me being a developer when I asked about cooking?" Well, the reason is this developer had in their customization on T3 chat information about themselves, including what is their job and they answered engineer. And since that is now in the context, you bet your butt that the Gemini models are going to use it.
It doesn't matter if it's not relevant to the thing you're doing. If it exists in context, the model will acknowledge it. And Gemini is really bad about this. If you give Gemini information, it will use that information even if it is not at all relevant to the task it is trying to complete. So if you hand a Gemini model a thousand tools, it'll use the [ __ ] out of them, even if none of them are useful. But if you give it just a small handful of tools, in particular a bash tool, it can use that bash tool to do anything it needs to.
And this is a big part of why the bash tool is so powerful, because when you give a model bash, you don't have to give it too much else. And if the alternative is giving it an edit tool, an update tool, a rename tool, a move tool, a file check tool, a directory creation tool, and all these other things, it's going to use all of them, but it's not going to get anywhere. I like this framing from Reese here. Bash wasn't just a tool. It was the introduction of the first execution layer. LMS were now able to progressively discover tools, chain commands, g their outputs when they got too long.
It was the first execution layer that slipped in just as a regular tool. Bash is imperfect though. Think about the following problems we have with agents today. You want to share your signedin state between cursor, open code, and open claw so that those agents have access to things like a web app that you're working on. You want to share approval methods. So if you've approved of a command in one thing, you should be able to share it and have access to it in other things without having to manually approve every time. And those approvals are dangerous in their own way.
It seems unintuitive, but having the models and having the agents and harnesses constantly asking us if we approve or disapprove of a thing massively increases the danger surface area because it has numbed us to just hitting yes over and over. So much so that most of us, myself included, just run in dangerously skip permissions mode because we don't want to sit there and hit yes, you can grap, yes, you can cat, yes, you can check the git status over and over again. So, we just let it do its thing. There's lots of other fun problems here, too.
You want some agents to have access to some tools. You want to be signing to two different accounts at the same time for something. You want to know all possible operations that could be performed by your tools. You want to auto approve read only, but you want to require approval for writes and destructive actions. You want to apply wildcard approvals to certain functions. You need to know whether an AI action is destructive or not. And for teams, you want to be able to enable your sales team to call Salesforce, but not your engineers. all things that make sense in how companies and real systems work, but you're not going to figure that out with Bash.
The main reason why is there's no standards. Bash just lets you run commands and those commands can be formatted in any crazy way. The lack of standards around what actions are destructive and which aren't attempting to elicit input from the user and knowing everything that's available, doing wild card approvals, all those types of things. Bash just can't do that. There is no standard to know if a bash command is or isn't destructive. There is no standard to know if you have permission to run a certain command or not. There is no way the model can just do this.
And every single tool we use, every single CLI, every single thing we use is going to have its own solution, which means we have to go back to bloating context describing how each of these tools going to have these things checked and what we expect it to do. Or we can try and find a better way. And we're already seeing the worst thing, the alternative, which is assuming bash stays. We end up with all these companies who are making CLIs for things like Pop for Data Dog, the Google Workspaces CLI, the Poly Market CLI. God damn it.
Wonder if there's a poly market if Poly Market would make a CLI. There be a poly market for how long it'll take for the Poly Market CLI to fall out of date and break. Just saying. Not an ad, by the way. I [ __ ] hate all these gambling things so much. Don't gamble. You will lose money. If you want to feel like you're gambling, just go generate things over and over again with Gemini. It's basically gambling, but slightly less expensive. You may be thinking to yourself, well, the solution here is to make CLIs that let you call any API.
That's thinking too small. You're not building something that will enable every person in the world to interact with services. And Bash is not that solution. So what can we do? We need a typed environment with inputs and outputs, the ability to proxy calls along with this being cheap to run and portable and well isolated and all these other things. Ah, TypeScript is right there. I had not read this already. I had a feeling we would go in this direction, but it's fun to see. For context, one of my least favorite things in the world is MCP.
It is getting almost to the point where it can be useful sometimes for some things, but we're still barely even getting there. The vast majority of MCP servers you can integrate in your stuff are bad and just make your experience using AI worse. The vast majority. And one of the problems here is that these MCP servers are just piled with different commands you can run in them, context that you need in order to know how to use them. And the MCP servers once added as context will just take up so much of your context window.
It's not exactly the same, but it's relatively similar. Anthropic implemented searching for tools instead of just adding them all into context always. And you see here that this MCP server example they had had almost 40% of its space being taken up with just MCP information. 72,000 tokens of info about the MCP servers. That's insane because these specs are bad and bloated and awful. Code mode was Cloudflare's interesting alternative here where instead of trying to give all of the context to the model about the MCP servers and how to call them, what if they converted those to be TypeScript SDKs and had them in the codebase as a discoverable thing the model could use and write code against with way less context being used.
It doesn't need to know about everything. It can search the way it does for code or your MCP stuff instead. I have multiple videos going in depth on this. I recommend checking them out if you haven't. They're my MCP videos. But the TLDDR I'll give you here is that when you let the models write code to call these things instead, it made a lot of stuff better. Instead of having to do the query to get all of the users, get all that in context, and then find the one that has the specific field, it could filter it using code.
It could grab all the users and then dot filter for the one it wants and then return just the two rows you care about, not the 100,000 rows that exist in the codebase or in the database, whatever else. Instead of every single MCP call or tool call having to go back to the model to do the next step, the code can run do whatever filtering and other tool calls it needs to do. And then when it's done, it sends the result back to the model, helping reduce the context being wasted. And it turns out the models are really good at this.
It made the amount of tokens needed to do responses in many examples way lower. It made the speed that it got answers much higher. And it improved reliability because when you give a model a 100,000 things and tell it to filter for the one you want, it will do it 60 to 70% of the time. But if you ask code to do it, it'll do it deterministically 100% of the time. This method in their examples helped drop the average number of tokens used from 43,500 to 27,000, a nearly 40% reduction. It was also massively better latency and improved accuracy with a threepoint bump from 25.6 6 to 28.5 in a handful of benchmarks.
That's nuts. Turns out the models that were all trained to write code are pretty good at writing code. And it turns out an actual language has benefits over bash. So to go back to what Ree is saying, TypeScript is a very interesting solution here. Not just because Typescript is a language and bash is bash, but because Typescript can be executed in all sorts of different environments in different ways. Like in the isolates in your JavaScript runtime in things like V8 or Node or workers with Cloudflare or even in your own browsers, there are lots of different ways that you can isolate JavaScript processes so that they're safe to run next to each other and don't affect each other.
Which means you can have one Linux kernel that is running hundreds of users requests at the same time without having to use Docker and virtualize everything above. That's huge. That's magical. That's so powerful. And Typescript as a language is pretty useful here because once it becomes JavaScript, it doesn't have to be compiled or anything. You can just throw it into this virtual environment and be good because it's not a real virtual environment. It doesn't isolate. Funny enough, this is why Versell made just Bash because according to them, models are really good at using Bash, but giving each model access to a full computer to use Bash on is less than ideal.
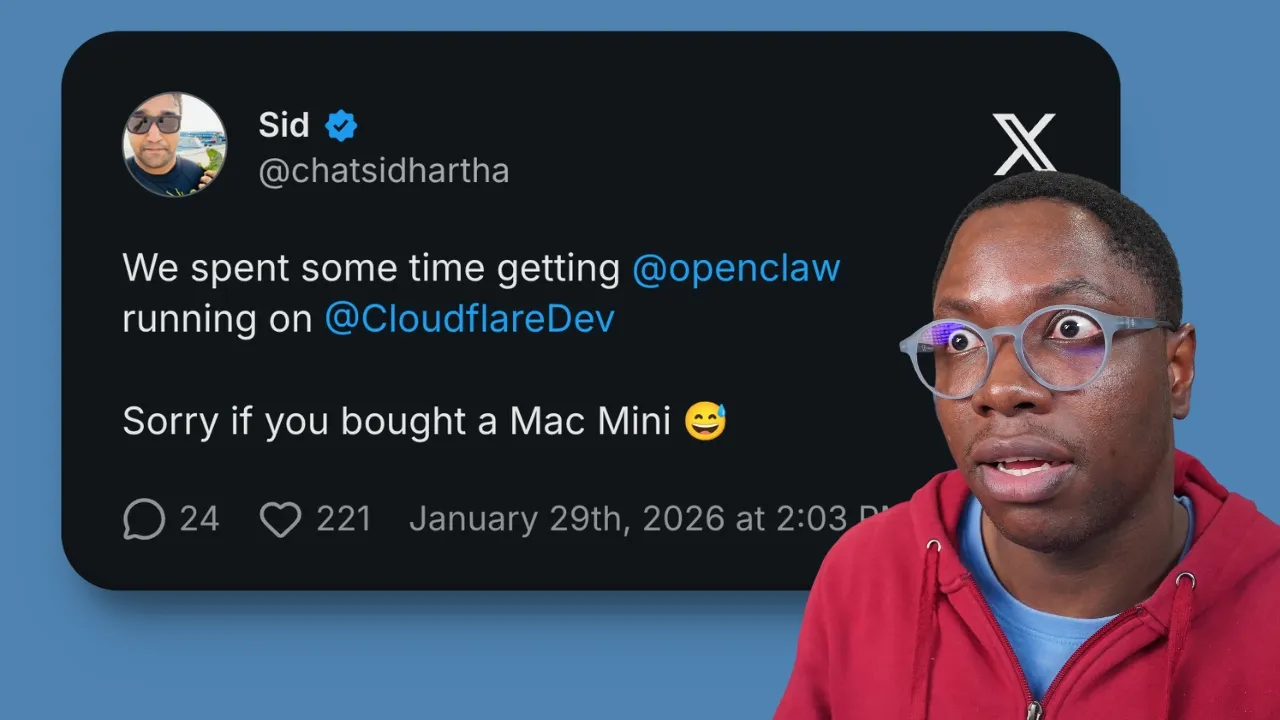
What if they could give the models bash to do things like find the right files, edit code, and do the other stuff they need to do, but fully virtually by giving them a fake bash that they can run commands with that doesn't actually touch your file system. It's just a virtual instance of bash in quotes written in Typescript that runs in Node or V8 or wherever else. This is super cool. It's so cool that it caused a huge drama between Cloudflare and Verscell that I just covered a few days ago. It is a very cool project.
However, as we are now establishing, Bash might not be the end- all beall solution here because it's it's missing so many things that are important, which is why Malta introduced just JS. Half a joke. They added JavaScript and TypeScript execution in just bash, which sounds kind of insane because it kind of is, but also just think about how powerful this is. If you have one server running node in one instance, and you want hundreds of people to be able to run agents and edit code, you can't give those agents access to bash on this server that hundreds of users are accessing things on.
And you definitely don't want them to have the ability to break out and touch things from other users of yours. Like if user A could access and edit the files for user B, everything falls apart. Just bash helps, but still bash. What if you wanted to be able to let the models write TypeScript that can run against all the files in your file system and figure out which ones matter or categorize them or do real things with the data in your file system? Well, you can't give them file system access because everything is on this server.
You don't want people to have access to another person's files. But what if each isolate was safe? What if each instance knew that only its data could be accessed in it and other people couldn't access that data and it couldn't access other people's data like they set up with just bash. That's what just JS is. It means you can let a model write an FS command and execute it in this library and it never leaves RAM. It never leaves this instance. It lives in its own little box that is safe. That's really cool. And I think we're going to see more and more stuff like this as we go forward.
or solutions that allow the agents to effectively be lied to that they're using a real computer with real bash on a real kernel and they don't know any better and they'll go behave accordingly and theoretically if they can write TypeScript as well in the same way they'll be able to get more useful information before they even run the command as to what they can and can't do. Let's go back to what Reese said. By creating a TypeScript environment for the LMS to call tools through you can create portable environments that can be shared with teams.
They're super lightweight to run. They have a strong ecosystem around them and they're strongly typed so you can get really creative with approval rules. Interesting. I really like the idea of portable environments that can be shared with teams. If instead of like trying to make a docker image that works properly for everyone, you just had a TypeScript file that did everything you needed called the APIs and whatnot to create the right environment for the agents or you just hosted this for everybody else to use against whatever tools they like. That is actually really exciting. The idea of a TypeScript file that configures the environment my agent works in.
That's very enticing. I like where this is going. There's limitless potential here. He wrote this for good reasons. He sees a really exciting future where once this stuff is set up, you could do crazy stuff like give the virtual file systems and stores based on your GitHub repos. Let your models call things like the AISDK to do generations in their own process and work sharing snippets of code. And there's so much cool [ __ ] you can do here. And everything we've done so far has felt like hacks to try and get around the fact that Bash isn't built for any of this.
That's why Reese built Exeutor, which is his attempt to try and figure out how to make an environment that the AI models can use to execute things safely. That's why Dax is experimenting with getting rid of the bash tool in open code entirely. These agents write JS fine. So, what if they just wrote JS to do what Bash would have done in the past and then they could work with tools like Rivet, which is a secure execution layer, and Sandbox. There's more and more of these sandbox companies coming up, and a lot of them are really cool.
Obviously, Daytona is a sponsor. I like them a lot. I think they're one of the best solutions right now, but definitely look around if you're looking for things like this. I still think just Bash is my favorite thing in the space, even if Bash isn't ideal. This layer for virtualization makes so much sense for me and it is a place that agents can execute to do things just that clicks in my head. It is very clear we are still in the early days of figuring all of this out. The question of where will our agents run and what will they have permission to do and edit and run in is all open questions that we don't have answers to yet.
But I'm excited to see where we end up as an industry. Similar to how we don't have the UI for how we're going to code with agents figured out. We don't have the environments figured out either. We really are in that weird space where everything we use every day has a meaningful chance of changing because of how AIs work in general. Like all of our AI agents don't fit well in the tools we use today. It was a fun coincidence that they work well enough with Bash, but we don't know what the best thing for them is yet and it's going to take a while for us to find it.
And it might be you who finds it. I hope you guys watch these videos and see the opportunities that I'm trying to present. I'm trying to make sure y'all understand how much [ __ ] can change right now and that any one of us can be the one who changed it. There's an old Steve Jobs saying that I think about a lot. Every single thing around us was made by a person just like you or me based on their understanding of the world. The world itself is changing right now and all of us have a chance to help shape where it goes.
So take these opportunities to do interesting things. Build with these tools. Run into these problems. Try to solve them yourself. Look at how other people solve them and play with those solutions. Modify them. Change them. Fork them. Play around. Go download T3 code and tear it to pieces. Build your own internal fork that you use for yourself or your team. go break and rebuild all of these things because the future looks very different from how today does. There's such a fun opportunity here and I hope more of you guys take it. It's been so cool to see all the UIs you're building based on my previous videos about the interfaces we use and I can't wait to see how much further you go with things like this.
Let me know how y'all feel and what the sandbox of the future is in your mind. And until next time, peace nerds.
More from Theo - t3․gg








Get daily recaps from
Theo - t3․gg
AI-powered summaries delivered to your inbox. Save hours every week while staying fully informed.