AI benchmarks
7 videos across 6 channels
Recent videos frame AI benchmarks as not just raw numbers but a look at practical progress and deployment realities. They spotlight Kimi K2.5’s multimodal prowess and swarm-enabled tasking alongside licensing and cost caveats, describe Poetic’s meta-system for scalable, automated problem-solving that can outperform base models at lower cost, and survey GPT-5.4’s benchmark gains amid safety, autonomy, and governance debates. Together, they probe how far benchmarks translate into real-world capabilities and competitive strategies in the rapidly evolving AI landscape.

DEEPSEEK V4 + OPENCODE + SUPERPOWERS IS ABSOLUTELY INSANE
The video tests DeepSeek’s V4 Flash and Pro models against GPT-5.5, sharing early results and opinions on open-source Ch

Kimi Code + Kimi 2.6 Just Changed EVERYTHING
The video tests Kimmy K2.6 inside Kimmy CLI, expressing strong skepticism about benchmarks while evaluating the model's

It's all fake
The video argues that AI benchmarks and online metrics are broadly unreliable and easily gamed, illustrating how tests,

Anthropic’s New AI Solves Problems…By Cheating
The video critiques Anthropic's Mythos paper by examining claimed autonomous flaw discovery and benchmark performance, w
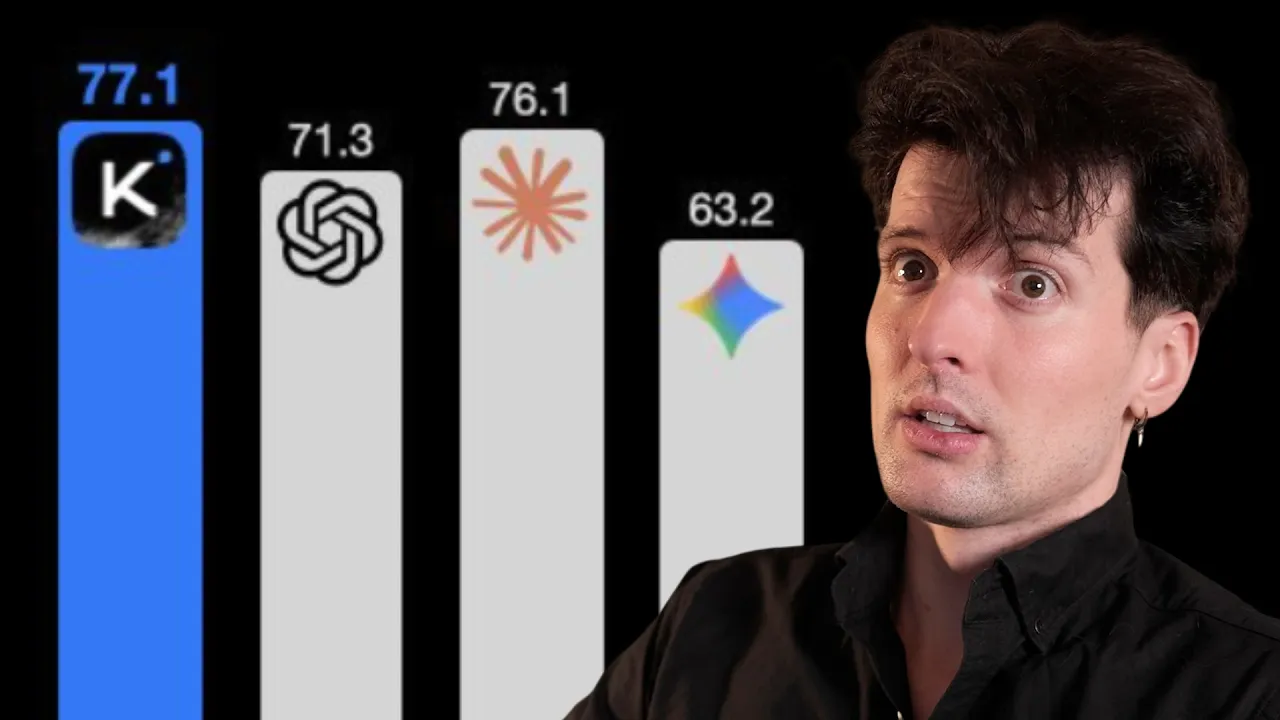
Kimi K2.5 might be my new favorite model...
The video highlights Kimmy K2.5 as a major openweight model leap, showcasing strong multimodal abilities, agent swarms f

The Powerful Alternative To Fine-Tuning
Ian discusses the rapid evolution of AI, introducing Poetic and its recursive self-improving meta-system that builds hig

What the New ChatGPT 5.4 Means for the World
The video surveys rapid AI progress centered on OpenAI’s GPT-5.4 and related models, comparing their benchmark performan